

Cloudera Director enables self-service provisioning and management of CDH and Cloudera Enterprise Data Hub in the cloud. Running Cloudera Enterprise on top of public cloud infrastructure allows you to pay only for the resources you need to meet your data processing demands.
Amazon Web Services (AWS) provides the ability to bid on spare Amazon EC2 computing capacity at a discount through Amazon EC2 Spot instances. With Cloudera Director, you can configure clusters to use Spot instances to improve workload execution time and save costs. As a trade-off for the discount, AWS may reclaim this computing capacity at any time. Google Compute Platform allows you to create Preemptible Virtual Machines that can similarly be reclaimed.
In order to support Spot instances and Preemptible Virtual Machines, Cloudera Director is now resilient to unexpected instance terminations while bootstrapping or growing a cluster. Also, Cloudera Director can automatically re-provision terminated instances to maintain the full intended capacity of the cluster.
This blog post goes into the details of fault injection testing introduced to identify vulnerable areas of Cloudera Director, and to demonstrate the high degree of resilience that we are now able to provide. It will also introduce the Automatic Repair feature that kicks in when instances unexpectedly disappear. This blog post was written using AWS Spot instance terminology for clarity but the results apply equally to Google Compute Platform’s Preemptible Virtual Machines.
Using Spot Instances with Cloudera Director
Figure 1 shows the Spot Instance Price History for a single day, taken from the AWS Management Console. Qualitatively, the price is steady with some periods of price spikes. Using a simple bidding strategy of bidding a fixed price will work great most of the time. Picking a higher bid price, for example 75% of the on-demand price, will protect you against price fluctuations of up to 75% of the on-demand price. Lower bid prices, like 35% of the on-demand price, will protect you against sustained higher prices. Regardless of your Spot bid, you pay the spot price for your instances. The AWS Spot Advisor analyzes historical pricing information and can be used to inform your bidding decisions. It is important to consult a tool like the spot advisor or to view the Spot Instance Pricing because Spot prices vary per region, availability zone, instance type, etc.
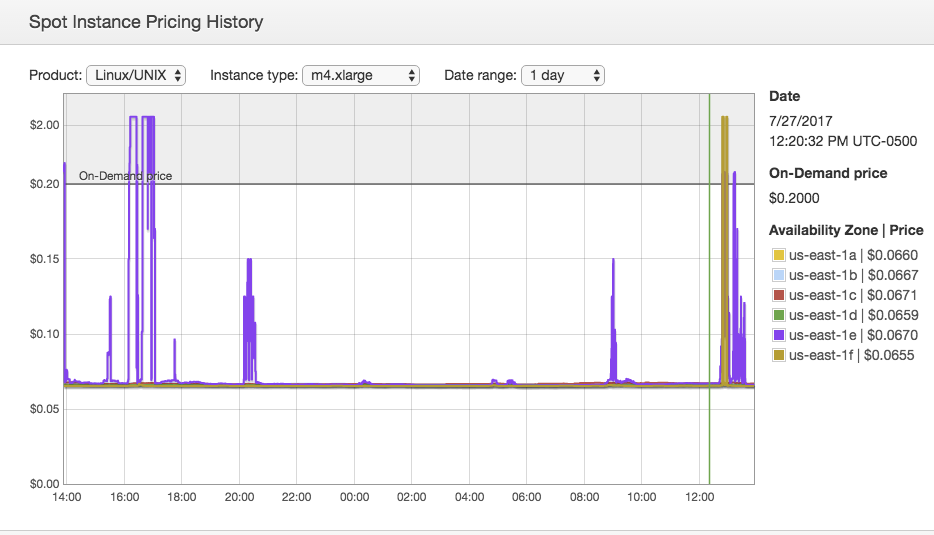
Figure 1. Example Spot Instance Pricing History.
You can configure Spot instances in Cloudera Director’s instance templates. These instance templates contain a flag indicating whether Spot instances should be used, as well as a field specifying the bid price for those instances.
Each instance group in the cluster template includes a field that indicates the minimum number of instances required in that group for the cluster to be considered successful. Cloudera Director will continue with bootstrapping or growing a cluster if the minimum count for each instance group is satisfied. Spot instances should not be used for instance groups that are required for the normal operation of the cluster, such as HDFS DataNodes. Instance groups configured to use Spot instances should set their minimum number to zero with the expectation that the instances may not be provisioned due to the Spot bid price being lower than the Spot price.
See Cloudera Director’s documentation on Using Spot Instances for more information on how to configure your cluster with Spot instances.
Resilience to Spot Instance Termination
Cloudera Director is considered resilient if it can bootstrap or grow a cluster successfully while instances are terminated at any point. While resilience is not a new feature in Cloudera Director, we have been working hard behind the scenes to improve how Cloudera Director behaves in the face of increased probability of instances disappearing, as is the case with Spot instances.
How do we know that Cloudera Director is resilient to Spot instance termination? Testing!
Testing Resilience with Spot Instances
The simplest way to know whether Cloudera Director is resilient is to bootstrap a cluster with Spot instances and run a workload. This will show how a cluster will behave in the real world. However, this approach is unsatisfying for testing because, with the right bid price, Spot instances are fairly stable. We use testing with actual Spot instances at multiple price points to benchmark our expected real-world performance. However, this testing is not comprehensive due to variations in Spot prices and price behavior over different instance types and availability zones.
There are three possible testing outcomes based on the selected bid price:
• Bid price exceeds the Spot price and instances are allocated.
• Bid price does not exceed the Spot price and no instances are allocated.
• Spot price fluctuates around the bid price. Instances are initially allocated, but then terminated when the Spot price rises above the bid price.
Case 1 behaves the same as when using on-demand instances. Case 2 is also uninteresting since the cluster should operate without the Spot instances as long as the minimum count for the instance group is set correctly to zero.
Case 3 is the interesting case. Simulation of Spot instance termination is required to adequately test Cloudera Director’s cluster bootstrap and grow features. We cannot rely on AWS to terminate the Spot instances in a timely manner for testing resilience, i.e., during cluster bootstrap or grow, because changes in the Spot price are unpredictable.
The process of bootstrapping or growing a cluster is a workflow composed of a series of tasks, such as allocating instances, installing packages, running scripts, and so on. We enhanced our test framework to intercept the transitions between tasks and allow the injection of code that terminates an instance. This instrumentation let us create tests that terminate instances before specific tasks. Spot instances can be terminated at any time, so we also configured tests to wait a random amount of time before terminating an instance. Termination injection allowed our tests to probabilistically cover each of the tasks over the course of many test runs. This simulation allowed us to explore the most interesting scenarios for using Spot instances.
Armed with the ability to terminate instances at any point during cluster bootstrap or grow, we were able to verify that Cloudera Director has a high degree of resilience when deploying clusters that use Spot instances.
Improving Resilience During Cluster Bootstrap and Grow
Cloudera Director’s bootstrap and grow tasks interact with the instances directly through SSH or indirectly through Cloudera Manager commands. Termination injection can reveal issues that exist in either type of interaction. Instance termination during direct interaction results in network-related errors such as socket timeouts, read timeouts, or no route to host. There is usually no way for any task that encounters one of these errors to continue, so the task must fail. Instance termination during indirect interaction will return errors through the Cloudera Manager API.
The general approach to improving resilience in the face of these failures is to isolate instances so their failures can be handled individually. Prior to this work many tasks were implemented to operate on batches of instances. The workflow was modified to split these tasks into multiple parallel tasks, allowing Cloudera Director to stop work on failed instances. Failed instances are removed from Cloudera Manager and, if necessary, terminated in AWS. Splitting the tasks does not affect cluster creation time because the tasks are run in parallel.
Some tasks, typically Cloudera Manager commands that affect the cluster as a whole, can only operate on the batch of instances. Cloudera Director cannot tolerate failure in these tasks. Accordingly, we improved Cloudera Manager’s resilience to instance terminations for issues discovered through termination injection or similar component and functional tests.
The improvements made in both Cloudera Director and Cloudera Manager along with the test coverage provided by termination injection have given us the confidence that cluster bootstrap and grow are indeed resilient to Spot instance terminations. This is not a time to rest on our laurels; we are continuing to enhance our testing to improve our confidence in our resilience to Spot instance terminations. Stay tuned for more improvements on this front!
Automatically Repairing Clusters
Cloudera Director has now added the ability to automatically repair a cluster. This feature relies on our ability to resiliently grow a cluster to ensure that repair does not fail.
Auto-repair will craft and submit a cluster update to replace instances that are either missing or terminated. Cloudera Director does not replace stopped instances, nor does Cloudera Director consider health as reported by Cloudera Manager in making repair decisions. Instances removed by the user through a shrink operation will also not be repaired. Missing instances occur when Cloudera Director is unable to fully provision a cluster. A cloud provider may fail to provision instances for a number reasons: the Spot bid price is too low, or the account hit some instance limit, or the cloud provider ran out of instances. The resulting behavior is that auto-repair will attempt to provision instances that could not initially be provisioned for any reason. Instances reclaimed by AWS due to Spot price fluctuations will end up in the terminated state and will be re-provisioned by auto-repair.
Auto-repair is triggered each time Cloudera Director’s cluster model changes in order to replace missing and terminated instances with as little delay as possible. Cloudera Director performs a periodic refresh (defaulting to 5 minutes) to update the cluster model. This includes finding and updating instance information from the cloud provider. This mechanism updates Cloudera Director’s cluster model with the latest state of each instance.
Auto-repair can be configured with a cooldown period to enforce a quiet time between updates to prevent flapping (repeated instance provisioning and termination) by giving enough time to wait out Spot price fluctuations before attempting to re-provision instances. Auto-repair does not submit cluster updates when the cooldown period is in effect. The cooldown period is tracked on a per-cluster basis and is set to 30 minutes by default. The cooldown period is also enforced after the Cloudera Director server starts and after any bootstrap or update is run.
Using the auto-repair feature can help realize the potential of Spot instances by ensuring that your cluster always has the computing capacity you need at the price you want.
Summary
Cloudera Director 2.5 has made some major improvements in the handling of Spot instances. Improved resilience makes cluster bootstrap and grow much more reliable while auto-repair ensures that your cluster is restored to full computing capacity after Spot instances are terminated.
If you’re ready to give the latest version of Cloudera Director a try, here are the ways you can get started.
• Download Cloudera Director from our website, where you can also find its user guide, to start fresh or upgrade from an existing installation.
• Use these sample configuration files and scripts as starting points for setting up your clusters.
• Send questions or feedback to the Cloudera Director community forum.
David Han is Software Engineer for Cloudera Director.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht