

De laatste tijd zie je dat steeds meer bedrijven aan de slag gaan met Power BI. Het is een populair product, men heeft er weleens van gehoord en het is makkelijk zelf, en gratis, te downloaden. Self-service BI is populair. De drempel om een dashboard te bouwen is laag en het ziet er al snel erg mooi en interactief uit. Wat is nu nog de meerwaarde van een datawarehouse of een semantische laag als iedereen gewoon zelf met power BI aan de slag kan?
Databron
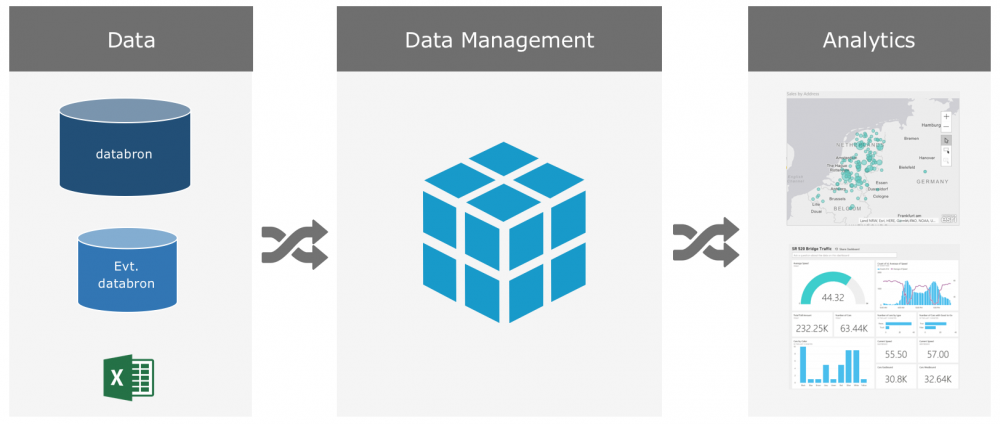
Als men binnen een organisatie zelf aan de slag gaat met Power BI als self-service tool zien we waak dat Power BI wordt gevoed door Excel files. Deze Excel files worden vaak uit een bronapplicatie geëxporteerd en daarna, voordat ze in Power BI worden geladen, als dan niet bewerkt. Om een rapportage te updaten moeten een aantal handelingen worden verricht en de herkomst van de data van de verschillende dashboards is soms zelfs lastig te achterhalen. Voor je het weet wordt de organisatie gestuurd op dashboard waarvan eigenlijk niemand ooit goed heeft gecontroleerd of de data echt wel klopt.
Organisaties die de data al rechtstreeks uit het bronsysteem halen denken deze problemen voor te zijn, maar ook dan kan het erg nuttig zijn om na te denken over de architectuur. Een model in Power BI is zo gemodelleerd, maar waar leg je dan je definities vast en hoe zorg je dat de tabellen altijd op de goede manier aan elkaar worden gekoppeld?
Semantische laag
Door het gebruik van een semantische laag tussen de database en de rapportage tool kunnen een hoop van bovenstaande problemen weggenomen worden. Een semantische laag (of data management laag) is eigenlijk een fysieke of virtuele laag tussen de databron(nen) en de rapportage tool waarin de data vertaald wordt naar een makkelijk te gebruiken model voor de eindgebruiker. Een veel gebruikte oplossing hiervoor binnen de Microsoft BI-stack is kubussen. Deze bieden tevens nog het voordeel dat je hierop met Power BI live kan connecteren. Wat is nu de meerwaarde van een semantische laag tussen de database en de rapportage tool?
• Definities kunnen op een plek worden vastgelegd
• Modellering hoeft maar een keer te worden gedaan
• De modellering wordt juist gedaan, waardoor iedereen over de juiste cijfers beschikt
• Een eindgebruiker hoeft geen verstand van databases te hebben
• Men kan rapporteren aan de hand van businesstermen
• Afhankelijk van de architectuur wordt het bronsysteem niet continu belast met query's
• Er kan met verschillende tools over dezelfde data worden gerapporteerd
Ontwikkeling onder controle
Door het aanbieden van een goede en bruikbare rapportageomgeving aan de eindgebruikers kan ook een wildgroei aan rapportages binnen de organisatie voorkomen worden. Alle rapportages maken op dezelfde manier een connectie met verschillende bronsysteem en deze kunnen op een gestructureerde manier, al dan niet in de cloud, worden opgeslagen. Door middel van de verschillende security mogelijkheden kan ook nog bepaald worden wie welke data mag zien en wie welke rapportages kan wijzigen of ontwikkelen.
Conclusie
De opkomst van self-service BI is zeker niet verkeerd, maar denk als organisatie wel goed na over de inzet van de verschillende tools en tevens ook de beheerbaarheid ervan. Power BI gebruiken om even snel een analyse te doen op bepaalde data kan heel waardevol zijn, maar als de rapportages een dagelijks onderwerp van gesprek worden is het wellicht toch goed om even kritisch naar de architectuur en de inzet van de tool te kijken.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht