

In april 2019 is QUIPU4 gelanceerd tijdens de BI & DW Summit. Tijdens de lancering beloofde het team achter QOSQO dat de nieuwe modulaire opzet het mogelijk maakt snel modules met nieuwe functionaliteit te kunnen ontwikkelen, die door klanten kunnen worden gebruikt. Deze blog gaat in op de nieuwe features Meerdere tijdlijnen en Gepartitioneerd laden.
QUIPU 4 is een platform dat model-naar-model-conversie ondersteunt. Dit is waar het product zich onderscheidt van gangbare ETL-tools en andere datawarehouse automatiseringstools. Deze tools werken doorgaans goed bij het transformeren en manipuleren van data op entiteit- of attribuutniveau, maar missen de ondersteuning voor het definiëren en ontwikkelen van transformaties op modelniveau. Het is op dit hogere niveau dat patronen kunnen worden gevonden en toegepast en dus kunnen worden gegenereerd. Dit levert volgens QOSQO een veel efficiëntere manier op om snel nieuwe data solutions te ontwikkelen.
Use case: Meerdere tijdlijnen
Een tweetal klanten van QUIPU4 heeft behoefte aan het kunnen registreren van meerdere tijdlijnen, zoals aanwezig in de bronsystemen. Om die reden is de functionaliteit van generatie van het historisch data-archief(HDA) uitgebreid. Naast de reeds aanwezige functionaliteit van registratie van tijdstip van laden van data in het datawarehouse is het nu mogelijk om net zoveel extra tijdlijnen te definiëren als nodig worden geacht.
Hele bekende voorbeelden van extra tijdlijnen zijn de mogelijkheid om:
• de datum te registreren in het HDA wanneer iets in de echte wereld heeft plaatsgevonden;
• de datum te registreren in het HDA wanneer de betreffende data is geregistreerd in het bronsysteem.
Dit maakt het mogelijk om willekeurige tijdstippen van gebeurtenissen te registreren. Ook als deze op verschillende momenten hebben plaatsgevonden.
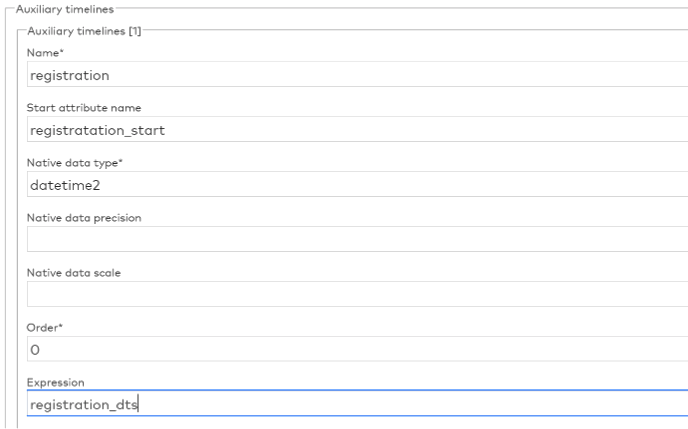
Figuur 1: Creatie additionele tijdlijn in QUIPU4.
Een voorbeeld:
Iemand verhuist op 1 maart (gebeurtenis in de échte wereld) maar geeft de verhuizing pas door op 17 maart aan de opstalverzekeraar (registratie in het bronsysteem). De geassocieerde data wordt éénmaal per maand in het HDA geladen. De eerstvolgende keer is 1 april.
Net als bij het reguliere deltadetectiemechanisme is het mogelijk voor deze twee tijdslijnen ook wijzigingen te detecteren en deze dan te end-daten, zodat wijzigingen, net als bij deltadetectie, worden ‘gestapeld’ in het HDA. In bovenstaand voorbeeld zou dat kunnen spelen als de doorgegeven verhuizing niet op 1 maart maar al op 1 februari heeft plaatsgevonden. Vanuit businessperspectief kan het handig zijn om dit te kunnen achterhalen.
Use case: Gepartitioneerd laden
Wederom was een klantvraag leidend bij de ontwikkeling van deze feature. Gepartitioneerd laden, door sommigen ook wel FUELTA genoemd, een samentrekking van FUll load en dELTA load.
Deze vorm van laden van data staat toe om een vaste partitie van data te kunnen laden. Hiermee kan worden voorkomen dat door levering van een deelset aan data de aanwezige historie in het datawarehouse wordt verwijderd (door middel van end-dating). Dit is handig in het geval van bijvoorbeeld het laden van financiële systemen, die alleen het laatste boekjaar aanleveren, terwijl alle voorgaande boekjaren al eerder in het datawarehouse zijn geladen. De functie is overigens generiek geïmplementeerd en kan ook worden toegepast op andere vormen van partitionering van data, zoals bijvoorbeeld regio.
Deze functie past alleen een ‘verwijder’-detectie toe op reeds aanwezige data uit de partitie. Teneinde de functie toe te kunnen passen, is een zogenaamde ‘partitie-expressie’ nodig. Deze is eenvoudig door de architect/ontwikkelaar aan te maken.
Voor meer informatie, een whitepaper en een uitgebreide handleiding kunt u terecht op www.quipu.nl. Bent u geïnteresseerd in QUIPU4, dan kunt u via de website een gratis trial-licentie aanvragen voor één maand. Desgewenst verzorgen we een demo.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht