

One of the new features in SQL 2017 is a way to save Graph Data. First time I heard the term 'graph' I was stunned... Graph Data? First thing, I thought that came into my mind: 'Why would you save charts (graphs)'. Nevertheless, that is not what Graph Data is.
What is Graph Data?
When we are speaking about Graph Data we are not speaking about tables anymore but nodes and edges. A node can be compared with an entity, like person, employee, company or department. In addition, an edge is what relates the entities to each other. Both of them can have attributes.
Where do we use them?
First of all nothing that can be achieved with Graph Data, cannot be done with regular Relational Data. However, they can make it easier to express certain kind of queries. Especially if your application has complex many-to-many relationships, since it is very easy to add new relationships.
Learn by example
Nothing better than to learn from an example.
I used an example I found on Microsoft Docs. It is a Graph Database of a hypothetical social network that has People, Restaurants, and City nodes. All of the entities are connected to each other by likes, friends, …

Code and explanation
Database creation is identically the same as any other DB.
CREATE DATABASE graphdemo;
The first small thing that is different is the Node (or Entity) creation. It is created just like any other table, except that you need to add the ‘AS NODE’ part at the end.
CREATE TABLE Person (
ID INTEGER PRIMARY KEY,
name VARCHAR(100)
) AS NODE;
CREATE TABLE Restaurant (
ID INTEGER NOT NULL,
name VARCHAR(100),
city VARCHAR(100)
) AS NODE;
CREATE TABLE City (
ID INTEGER PRIMARY KEY,
name VARCHAR(100),
stateName VARCHAR(100)
) AS NODE;
To create the Edges (or Relations) it’s as simple as creating an “empty” table and add ‘AS EDGE’ at the end. But in case you want to add an attribute to a relationship. For example a ‘Person’ likes a ‘Restaurant’ and you want to let them give a rating. Then you can have ‘rating’ as a attribute of the ‘likes’ relations.
CREATE TABLE likes (rating INTEGER) AS EDGE;
CREATE TABLE friendOf AS EDGE;
CREATE TABLE livesIn AS EDGE;
CREATE TABLE locatedIn AS EDGE;
What about data insertion? Nothing-special at least for Nodes.
INSERT INTO Person VALUES (1,'John');
INSERT INTO Person VALUES (2,'Mary');
INSERT INTO Person VALUES (3,'Alice');
INSERT INTO Person VALUES (4,'Jacob');
INSERT INTO Person VALUES (5,'Julie');
INSERT INTO Restaurant VALUES (1,'Taco Dell','Bellevue');
INSERT INTO Restaurant VALUES (2,'Ginger and Spice','Seattle');
INSERT INTO Restaurant VALUES (3,'Noodle Land', 'Redmond');
INSERT INTO City VALUES (1,'Bellevue','wa');
INSERT INTO City VALUES (2,'Seattle','wa');
INSERT INTO City VALUES (3,'Redmond','wa');
Before we go on, execute following query:
SELECT * FROM Person
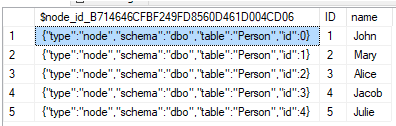
You will notice that except the ID & Name an extra column is available $node_id… Although ID is the Primary Key for the Graph Database this column will be used to make any relations, so this is what we will use to add data to our edge (relation) tables.
Create some relations with following query:
INSERT INTO likes VALUES ((SELECT $node_id FROM Person WHERE id = 1),
(SELECT $node_id FROM Restaurant WHERE id = 1),9);
INSERT INTO likes VALUES ((SELECT $node_id FROM Person WHERE id = 2),
(SELECT $node_id FROM Restaurant WHERE id = 2),8);
INSERT INTO likes VALUES ((SELECT $node_id FROM Person WHERE id = 3),
(SELECT $node_id FROM Restaurant WHERE id = 3),7);
INSERT INTO likes VALUES ((SELECT $node_id FROM Person WHERE id = 4),
(SELECT $node_id FROM Restaurant WHERE id = 3),5);
INSERT INTO likes VALUES ((SELECT $node_id FROM Person WHERE id = 5),
(SELECT $node_id FROM Restaurant WHERE id = 3),6);
INSERT INTO likes VALUES ((SELECT $node_id FROM Person WHERE id = 1),
(SELECT $node_id FROM Person WHERE id = 5),0)
INSERT INTO livesIn VALUES ((SELECT $node_id FROM Person WHERE id = 1),
(SELECT $node_id FROM City WHERE id = 1));
INSERT INTO livesIn VALUES ((SELECT $node_id FROM Person WHERE id = 2),
(SELECT $node_id FROM City WHERE id = 2));
INSERT INTO livesIn VALUES ((SELECT $node_id FROM Person WHERE id = 3),
(SELECT $node_id FROM City WHERE id = 3));
INSERT INTO livesIn VALUES ((SELECT $node_id FROM Person WHERE id = 4),
(SELECT $node_id FROM City WHERE id = 3));
INSERT INTO livesIn VALUES ((SELECT $node_id FROM Person WHERE id = 5),
(SELECT $node_id FROM City WHERE id = 1));
INSERT INTO locatedIn VALUES ((SELECT $node_id FROM Restaurant WHERE id = 1),
(SELECT $node_id FROM City WHERE id =1));
INSERT INTO locatedIn VALUES ((SELECT $node_id FROM Restaurant WHERE id = 2),
(SELECT $node_id FROM City WHERE id =2));
INSERT INTO locatedIn VALUES ((SELECT $node_id FROM Restaurant WHERE id = 3),
(SELECT $node_id FROM City WHERE id =3));
INSERT INTO friendof VALUES ((SELECT $NODE_ID FROM person WHERE ID = 1),
(SELECT $NODE_ID FROM person WHERE ID = 2));
INSERT INTO friendof VALUES ((SELECT $NODE_ID FROM person WHERE ID = 2),
(SELECT $NODE_ID FROM person WHERE ID = 3));
INSERT INTO friendof VALUES ((SELECT $NODE_ID FROM person WHERE ID = 3),
(SELECT $NODE_ID FROM person WHERE ID = 1));
INSERT INTO friendof VALUES ((SELECT $NODE_ID FROM person WHERE ID = 4),
(SELECT $NODE_ID FROM person WHERE ID = 2));
INSERT INTO friendof VALUES ((SELECT $NODE_ID FROM person WHERE ID = 5),
(SELECT $NODE_ID FROM person WHERE ID = 4));
Let’s analyze 1 insertion:
INSERT INTO likes
VALUES ((SELECT $node_id FROM Person WHERE id = 1),
(SELECT $node_id FROM Restaurant WHERE id = 1),
9);
Although we only created a table for Likes with one column, we are inserting three values.
An Edge table exists standard out of three columns:
• edge_id (automatically filled in)
• from_id
• to_id
So in this insertion we are saying that Person with id = 1 ‘Likes’ Restaurant with id = 1, and gives a rating of 9.
Now the interesting part, querying the data. Some examples:
You want to find all the restaurants that John likes.
SELECT Restaurant.name
FROM Person, likes, Restaurant
WHERE MATCH (Person-(likes)->Restaurant)
AND Person.name = 'John';
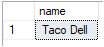
In our table selection we choose all the tables we need, and then we use the MATCH syntax (new for Graphy Data). This is used to tell what kind of relationships you want to use. In a standard relational database this would always be the same. You would have a specific table where you keep track of which Person likes which Restaurant. But with a Graph Database we can also keep track of which Person likes which Person.
SELECT p2.name
FROM Person p1, likes, Person p2
WHERE MATCH (p1-(likes)->p2)
AND p1.name = 'John';
With above query we search for People that John likes. Notice we make use of the same Edge table ‘Likes’.
Some more advanced queries to show the power of graph data.
Find Restaurants that John’s friends like:
SELECT Restaurant.name
FROM Person person1, Person person2, likes, friendOf, Restaurant
WHERE MATCH(person1-(friendOf)->person2-(likes)->Restaurant)
AND person1.name='John';
Find people who like a restaurant in the same city they live in
ELECT Person.name
FROM Person, likes, Restaurant, livesIn, City, locatedIn
WHERE MATCH (Person-(likes)->Restaurant-(locatedIn)->City AND Person-(livesIn)->City);
This example should have given you a small overview of what Graphy Data is and what the possibilities are. If you want to learn more about the architecture behind it, then visit Microsoft Docs.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht