

In the past few weeks and months, I got these very interesting questions which brought up a several times. So, I try to explain here my understanding and my thoughts. If you have a diverging view, feel free to contact me on LinkedIn for a discussion. If I misunderstood any part of the data mesh concept, please let me know.
It might be helpful to understand my background and what formed my opinion to understand my argument. I have been working with data since 2000. I have seen different technological evolutions like Sybase clients migrating to Oracle and Oracle clients migrating to cloud databases as Snowflake. I have witnessed Inmon 3NF modeling approaches being sometimes replaced or supplemented by Dimensional Modeling and the rise of Data Vault modeling.
I have seen Data Vault modeling always as an evolution of Inmon 3NF modeling to be used in many cases in conjunction with a Dimensional output for reporting purposes.
Over past 22 years, we have also seen, again and again, business users hoping for faster delivery of reports — simpler understandability of the data, and many more things. The result of such demands was sometimes leading to a different technology or different modeling approach.
In other cases, it started a discussion about how much should be centralized (specialized team) or decentralized. This tension is not new.
I understand, and that is my personal opinion: Data Mesh is an answer to the challenge that the central data team can become a bottleneck in certain companies using a centralized approach. And I perfectly understand that situation. I’ve been there and seen it. Honestly, I was a part of this problem.
As a result, I shared many points of view expressed in the work of Zhamak Dehghani. Still, I think, this approach applies best to some big enterprises with the resources to add data specialists into different domains.
My argument is that mid-sized and even larger companies could profit better from centralized teams by using model-driven automation to remove the bottleneck in the centralized teams as an alternative solution. Here I might point out that I could be biased as working for the Datavault Builder team – DWH automation is our thing.
Still, working for a bigger corporation where automation is not enough, as it alone doesn’t solve scalability completely, decentralization with a formalized approach as expressed in “Data Mesh” might be the right thing for you. In the following lines, I will discuss Data Vault vs. Data Mesh in this specific context.
Data Vault vs. Data Mesh?
If you prefer to watch a video instead of reading, you can find the recording from the Knowledge Gap conference here.
Significantly shortened and my interpretation of what I’ve read: Data Mesh describes that Enterprise Data Models are dead. You should split up your data modeling and implementation of your “data flows” into domains and assign it to independent teams – the domains.
Does this mean Data Vault is removed from that equation? I don’t believe so.
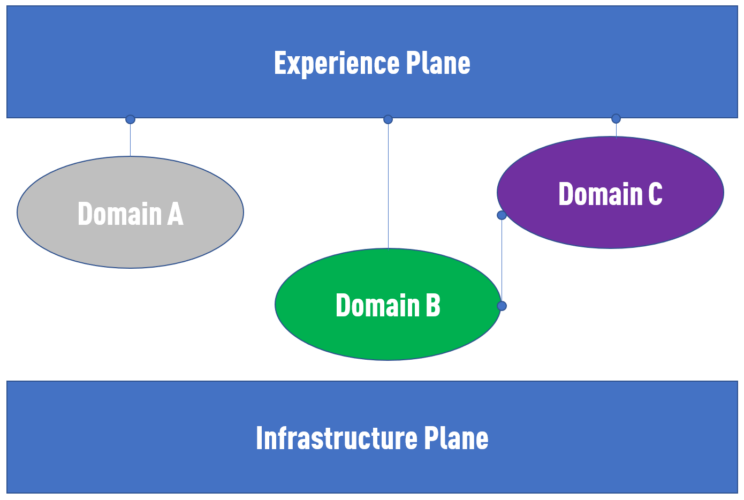
We see different data product providers between the infrastructure and the Mesh “Experience Plane.” Data Mesh is not prescribing the domain teams how to create them. In many cases, I would advocate that this is the perfect place to use an automated Data Vault approach.
Why? As if you got stuck with ETL approaches in the past, splitting them up into smaller domains may solve the scalability issue of the centralized data team and reduce some complexity. Still, it doesn’t remove many other problems, like missing documentation or a lot of manual work.
You know what I mean if you ever needed to reverse engineer some ETL flow to understand the business logic implemented.
Model-driven approaches start on the opposite with the understanding of what the data is about. We also had some awful experiences with Enterprise Data Models in the past as it took months to create them, a doctorate to understand them, and the data team ignored them as they were too abstract. Because of this experience, I know many people want to eliminate data models completely.
Still, we need them as they provide a lot of value and solve many issues, but also, we need the right approach to them.
Data Vault solved problems of the 3NF enterprise data model by using loose coupling between entities, allowing you to start small with your data model, implement it right away, and expand it later. This approach creates value early on and makes you agile.
On the downside, Data Vault creates, by hyper-normalization, a lot of technical objects. The result is that you would need a lot of data engineers in your domain teams to implement a Data Vault manually, and all of the implementations would be different. This approach means that if you want to add sidecar implementations, you must invent it for every domain repeatedly.
And here I can return to my favorite subject: automation. Automation will help you within the domains to reduce the amount of work and knowledge necessary to implement your Data Products by transforming a data model automatically into working code.
It will also solve many of the requirements defined by Zhamak Dehghani, like getting a clear data lineage and sorting out the historicization of the data, and many more.
For example, in the Datavault Builder, you will also get automated infrastructure, interfaces to inject your sidecars, and visual tools to define your Data Products, which will be a denormalized view on the very normalized Data Vault core.
Also, the model is versioned using the standard software approach using GIT-flow, which resolves any issues you could expect in the model and data product deployment.
Through Docker deployment and the provided APIs, you can set up your CI-CD workflow in a straightforward way.
As an automated Data Vault approach is model-driven, it will also allow you to generate and query all the model and run-time metadata described in the book without any manual development.
I think this is a perfect symbiosis. Does this mean every data domain should use an automated Data Vault implementation? Probably not.
As described by Zhamak Dehghani, the implementation within the domain shouldn’t be prescribed as some teams dealing primarily with non-historized machine data might decide on some non-modeled Kafka alternative implementation for a good reason. But teams needing to bring data together from different sources and a need to integrate them are for sure well off with it.
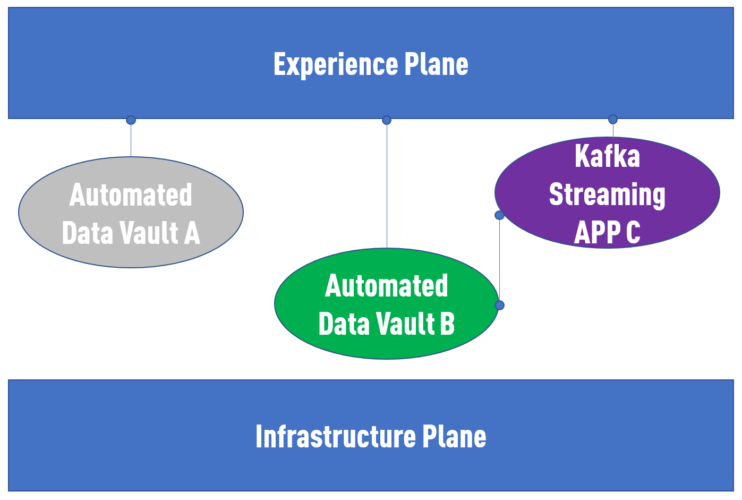
To conclude: Data Mesh + Data Vault is the answer. To be more precise: Data Mesh + Data Vault + Automation.
Central vs. decentral data model
The “Data Mesh” book remains vague in specific implementation details. And please don’t get me wrong: that is no critique. I think it has to, as it opens up a vision that can be implemented in many different ways. But from my perspective, I always start thinking about a concrete implementation of a specific architecture and how it will work out down the latest detail. So, this part is about how to implement it and make it operational.
We understand that the modeling responsibility can be shared between teams – in Data Mesh terms between domains. We have been doing that for years as an example in multinational companies with a central platform team and local data teams knowing the country specifics.
The central team defines central entities like the “customer” or the “product.” Now the first people hopefully start complaining about creating roadblocks again that we wanted to remove by adding centrally designed entities!
Hear me out: I’m not advocating for creating a central implementation of these objects. Just a conceptual definition that these objects exist. This abstract definition would correspond to drawing an entity onto your canvas in an ER world. In Data Vault, it would be a hub. Both cases give this entity/hub a unique ID that can be recognized throughout all the domains. We are using smart-keys in the Datavault Builder to identify these concepts, but technical IDs could also work for you.
Now that you have established that these concepts exist, you can distribute these “prototypes” into the different domains. Every domain would run its instance of the Datavault Builder. The domain teams will decide how to fill these concepts with data (i.e., which subset of customers go into their implementation of the “customer”) within their instance, which attributes they store about these customers, and which business rules shall apply to them.
This process of centrally defining the existence of things and distributing the definitions to the data domains can be completely automated in the Datavault Builder. This approach is possible as our data models like the central-one and the local-one are created so that they can be branched and merged through a GIT process. This design means that this process is not blocking any domain teams or create additional work for them.
On the contrary: if they believe that a concept they have within their domain should be used in other domains too (like being linked from other concepts) they can add it to the central model, which will be auto-distributed to the other teams.
One open point you will need to define for your company is if this central model will manage only the concept as such OR if you will also add a definition of the identifying key for an entity.
For example, you could create only a concept of a “Currency,” OR you could define that you have a “Currency ISO2” concept identified by the ISO 2 letter code and a “Currency ISO3” object for the 3-letter code. It depends on where you are on the centralization-decentralization journey.
The advantage of this approach is, as an example, that if the revenue assurance team creates a relation to the centrally created entity of a “customer,” it will define how you can relate data between the customer and the revenue assurance domains utterly automatic on the Experience Plane. If you also have defined the keys centrally, you will know it will work out even semantically.
This indication is given in the Data Product by using unique names for the key columns of centrally created entities like “Business Key of Customer.”
To recap in short, an example. In the central model, an entity called “customer” is created. One domain might implement details about the customer like name and address. The other one implements in the invoices data product a relation to customers. Both products are entirely independent. But by having a “Business Key of Customer” in both resulting Data Products, the experience plane knows how these 2 data products relate and can facilitate a query on the “joined” data set.
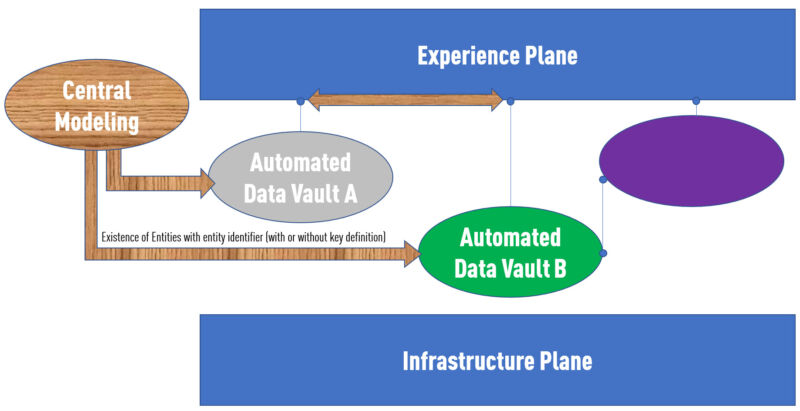
How to join between data domains
Now that you know how to join different data products from a logical perspective, the question remains how you are able to technically achieve that. In the Data Mesh book, it is proposed to use URI relations between objects. This approach might work out for smaller queries or by using technologies I’m unfamiliar with for larger amounts of data. My experience is that this approach could become difficult performance-wise.
But as the Datavault Builder is an ELT tool for most layers, we store all outcomes on a database level with virtual interfaces (views). It means that even if different data domains using the Datavault Builder do have completely isolated instances of the Datavault Builder running on separate databases but the same database technology like Snowflake, Azure Synapse, MSSQL Server, or Oracle, they can do joins using cross-database queries. These cross-database queries are driven through the Data Mesh Experience Plane, outside the single instances of a Datavault Builder.
If the different instance of the Datavault Builder does not use the same database technology or if you want to join it with non-relational data, you can use virtualization products as Denodo offers them.
My point is that there is a clear interface of every single Datavault Builder instance running within a domain handing out the data products as database interfaces (which can be served as APIs as well) and providing all the metadata and agreed-on key column names in an automated way to the Experience Plane so that this layer can do its magic. After that, the Experience Plane can decide to join different domains using database or virtualization technology and deliver the data as a database interface (JDBC / ODBC) or API to the consumers.
The Datavault Builder
In this section, I try to highlight why we believe the Datavault Builder is the right tool to implement Data Vault if creating a Data Mesh solution.
Cloud-Native – you can run it on a standardized infrastructure plane.
Automated infrastructure setup – using Docker deployment, you can start new environments using configuration
CI/CD – all deployment actions can be triggered using APIs.
Model-Driven automation – fewer technical skills are necessary within the Data Domains.
Git Flow-based – Data Models can be branched and merged, allowing for distributed development within the domain teams
Central & Distributed models – the built-in capability to create core elements centrally and distribute them to local domain-driven instances
Visual Data Product composition – the normalized core data store can be presented as a data product.
Automated data lineage
Automated documentation
All metrics are available in real-time.
The Data Vault approach allows you to start small and extend the domain model over time.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht