

It happens that from time to time I come across some statements about how databases work and how they shall be queried. And I like to read those recommendations. Especially if they come with a theoretical explanation. But even more, I like to read those comments if they come with tests that prove what the theory predicted. The best case always is if the scripts are published and can be reproduced.
But it is often the case that such claims about performance are made in a general way without any prove: it is always the case that pattern x performs better than y. And this might hold through if you have more knowledge about your data contents than the database might have. Or if there is a mathematical explanation for such behavior.
In my opinion in many cases about indexing or join strategies, the statements should be limited to database technologies and versions. Also, statements without reproducible tests should not be taken for granted but tested.
If I test something on SQL Server 2008 and compare it to SQL Server 2019 I will usually get completely different behaviors as SQL server evolved massively. If I compare Postgres with Snowflake and Exasol I get different behaviors as the later ones were created with analytic queries in mind.
That is the reason why I want to question the statement:
“Equi-Joins (inner joins) are always better than left joins”
Why does this matter
If the advice to use always a certain pattern is followed without testing it can lead to bad performance. As we are in the automation business with our Datavault Builder tool choosing the wrong pattern is multiplied hundreds or even thousands of times.
Why left joins might be better
First thing: in certain conditions, inner joins are better. As an example: They allow the query optimizer to start queries at either end of a join-chain and if this allows to limit the intermediate result set massively and to use for a few line row lookups on the other tables that are big and index it will help a lot. There are many other scenarios that you could think of that I won’t describe here in detail.
But that doesn’t hold through always. Imagine 2 scenarios:
• you have 10 tables. One has 15 million records and you have 9 Other Tables with 45 million records. All links are going from your 15m table directly to the surrounding tables. All 15m records have a matching entry in the 9 other tables.
- Execute INNER JOINs
- Execute LEFT JOINs
• you have 10 tables. One has 30 million records and you have 9 Other Tables with 45 million records. All links are going from your 30m table directly to the surrounding tables. 15m records have a matching entry in the 9 other tables. 15m records don’t
- Execute INNER JOINS => add dummy records to the 9 tables as otherwise you would loose the 15m nonmatching records
- Execute LEFT JOINS
That is the scenario I have executed on Snowflake 26th August 2021 (that is relevant as Snowflake is constantly improving).
My assumption was: left joins do perform better for this kind of query. Why? I did the same tests for SQL Server (2017) and Oracle (12c) 2 years ago and concluded that LEFT JOINS perform better based on the measurements I took for this scenario.
The theory here is: that at least in the second case the 30m table can be filtered before being joined so it should perform better. For the case where everything is matching I would expect the same or maybe a slightly worse performance as the FILTER on the 15m table could slow it down a little bit (a few percent maybe).
We will see that my expectations are in line with my measurements but still, I’m not 100% sure if my explanation is correct as I don’t have low-level access to the inner workings of the database. There could be alternative explanations that just not transmitting the dummy records 15m x is slowing down the INNER JOIN version. I simply don’t know for sure. But I see it is slower in most of the measurements. So if you understand on the DB level what is happening I’m happy to learn about it.
Also, in the case of using a left join, I can store less data as I can use a NULL value to indicate that there is no matching record in the other tables instead of storing it in a column/target table in the 2-column approach.
In the 1 column surrogate key approach, this NULL value can be coded in the key so it doesn’t generate that much overhead. But in the first case is uses 5x the space on disk! But still, in the second case, the table prepared for INNER JOINS uses 50% more space.
All values measured with 30m loaded.
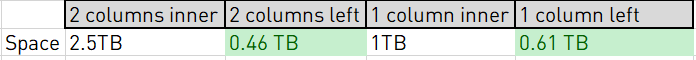
Testing
I have turned off result caches. But I didn’t cleared all Data caches after every query. Leading to some interesting results when the 2 columns inner 30m table was access so that the test to join 3 tables was slower than to join 6 tables in the next step. But as this is reproducible I assume it has to do with the data cache.
All tests were executed at least 3 times. Results were accepted if the deviation between runs was less than 10%.
Even the JOINs that need to be done an number of rows returned is everywhere the same, the results of the queries are not 100% the same: using INNER JOINs I get an entry in the 9 matching tables which I could use as dummy values like “N/A” etc. But I did in the output test to set this kind of dummies just using COALESCE and it didn’t make a difference so I removed that part from my query. But to improve the test it might make sense to set default values even using a CASE condition (if you want to differ match found but column NULL or no match).
Results
I have done 2 kinds of tests: used 2 columns to join between the 15m/30m table and the 9 others or only 1 one column (using a surrogate key to combine the first to fields)
In all cases with my data volume on Snowflake today the version with left joins performed about the same OR better. As always in certain runs, there were some outliers. Here is the output of some runs including the outliers like the 147s in the second run for 2 columns left join):




The 2 columns/9 sats load in the second run was a not reproducible glitch.
To be fair: the INNER JOIN on one column scans about 20-25% less data (as it doesn’t need to filter). But as this is a local scan it doesn’t hurt and speeds up the JOIN part so it looks ok.
Also what you see is that the joining on 1 column is as expected much more efficient than joining on 2 columns.
Note that in the S-sized run my expectation is that in the case that everything is matching the left column approach is about 5% less efficient in the 1 column scenario (as the filter is applied but not removing anything). BUT it is much better in the 2 column scenario as it creates less I/O.
I also changed the number of columns to output (selecting from 3 target tables instead of just one and check if it has an impact: no it hasn’t)

I have omitted to add the execution plans as they look very similar.
Summary
In certain cases, INNER JOINs do have a better performance than left joins. But not in all. I have shown with reproducible tests that in certain conditions LEFT JOINs don’t perform worse or even much better than INNER JOINs.
I don’t want to make a universal claim about my scenario. I just say: on certain databases in certain versions for certain queries LEFT JOINs might be the better option.
Also, we have seen that on Snowflake the join using 1 column is much better than using 2 columns.
Test yourself
As it is possible that I missed something. Did some key definitions wrong? Did I clear the caches the wrong way or wrote my SQL in a not optimal way? Please feel free to reproduce my results yourself.
The test script can be downloaded here: AUTOMATED_PIT_TEST


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht