

A common task for statisticians and data scientists is to model an outcome variable (also called a target variable). You might use an outcome model for purely predictive purposes. Or use it as a tool for studying the relationship between the outcome and a particular predictor of interest. For either purpose, Bayesian Additive Regression Trees models have proven to be an effective, easy-to-use tool for outcome modeling.
In this post, I provide an overview of Bayesian Additive Regression Trees (BART). I also demonstrate how you can train and score BART models by using the new BART procedure and Bayesian Additive Regression Trees Action Set in SAS Visual Statistics.
BART model overview
As a purely predictive model, BART models have many desirable features. By using a sum-of-trees ensemble to approximate the conditional mean of a response, BART models can do several things. They can incorporate a mix of categorical and continuous predictors, capture interactions between predictors without having to explicitly model interaction terms, and can handle missing values in the predictor variables. To fit a BART model, you use a Bayesian backfitting Markov chain Monte Carlo (MCMC) algorithm to generate posterior samples of the sum-of-trees ensemble by sequentially sampling updates to each tree. The final model consists of the posterior samples of the ensemble that you save for prediction. Therefore, unlike gradient boosting or random forest models that also use tree-based ensembles, BART models consist of many samples of the ensemble. As well, trees are not grown and added to the ensemble individually.
Advantages of BART models
Training a BART model and producing the posterior samples of the ensemble that make up the final model can be a time-consuming process. Scoring new data with a BART model can also be time-consuming for large data sets. This is due to the need to route each observation through all the saved samples of the ensemble and average the sample predictions. However, this modeling approach does provide you with some benefits. As described by Chipman, George, and McCulloch (2010), the default BART prior typically performs well in terms of model fit. This performance does not change significantly if there are small changes in the prior parameter. As such, a popular feature of BART models is that the default model specification typically performs well and hyperparameter tuning is not required. Moreover, you can assess uncertainty in the BART model predictions based on the variability of the posterior samples.
In addition to performing well as a purely predictive model, BART models have also proven to be useful when outcome modeling is used to study the relationship between the outcome and some predictor of interest. As described by Dorie et al. (2019), BART models have been observed to be a top-performing method in causal inference competitions.
BART models in SAS Visual Statistics
Starting with the 2022.1.1 release of SAS Visual Statistics, you can now train BART models of normally distributed response variables in two ways. You can either use the bartGauss action in the Bayesian Additive Regression Trees Action Set. Or you can use the corresponding BART procedure. BART models trained using either the BART procedure or bartGauss action can be saved as an analytic store. You can use the saved model to score new observations by using the ASTORE procedure, the bartScore action in the bart action set, or the score action in the astore action set. You can also use a saved BART model and the bartScoreMargin action to score predictive margins.
The predictive margins are obtained by first fixing the value of one or more of the input variables. This is followed by averaging the predicted values over the distribution of the covariates in an input data table. In cases where the proper causal assumptions hold, the difference between predictive margins that intervene on the same variable can correspond to a regression, or response surface, based approach to causal effect estimation.
Bayesian Additive Regression Trees example
This example uses the SmokingWeight data set. The data are available in the CAUSALTRT procedure documentation in SAS/STAT. Our example examines the effect of quitting smoking on individual weight change over a ten-year period. In this example, we assume that the causal assumptions needed for estimating the average treatment effect (ATE) hold. We therefore assume that the set of measured covariates represents a valid adjustment set. For more information about these assumptions and their importance, see the “Overview of Causal Analysis”.
BART procedure
To study the effect of interest we first fit a model by using the BART procedure. Then we save the model in an analytic store. Lastly, we use the CAS procedure to invoke bartScoreMargin action to compute the difference in predictive margins defined by the treatment variable QUIT.
The following statements use the BART procedure to fit a BART model for the response variable Change and create the analytic store mycas.store1.
proc bart data=mycas.smokingWeight seed=1976;
class Sex Race Education Exercise Activity Quit;
model Change = Quit Sex Education Exercise Activity YearsSmoke PerDay;
store mycas.store1;
run;
The BART procedure uses the traditional MODEL syntax, which lists the response (or target) variable and the predictor variables. Classification, or nominal, predictors, are listed in the CLASS statement. In this example, the predictor variables include the treatment variable of interest, Quit. Also included are the confounding variables that we assume represent a valid adjustment set. The model is fit using the default specifications. After 100 burn-in iterations, 1,000 samples of a 200-tree ensemble are produced and saved for prediction.
In this example, the model is fit in single-machine mode and all the posterior samples are run in a single chain. When you train a BART model on a cluster of machines, the default is to run multiple parallel chains. Then you divide the MCMC samples across the worker nodes. Due to the random sampling involved in generating the posterior samples, the fit of a BART model depends on the number of chains that are run. For reproducibility, you can specify the number of parallel chains to use, up to the number of available worker nodes. Or you can request that a single chain is run with each worker assigned only a portion of the training data.
CAS procedure
With the fitted model saved in analytic store mycas.store1, we use PROC CAS to invoke the bartScoreMargin action and compute predictive margins defined by the treatment variable Quit. The saved model mycas.store1 is specified by the restore parameter. The data table of observations to score is specified by the table parameter. Two predictive margins that involve interventions on the variable Quit are specified in the margins parameter. The predictive margin named “Cessation” sets the value of Quit to 1, which corresponds to a subject quitting smoking. The predictive margin named “No Cessation” sets the value of Quit to 0, which corresponds to a subject not quitting. These names are used in the differences parameter to request the difference between these predictive margins.
proc cas;
action bart.bartScoreMargin /
table = {name="smokingWeight"}
restore = {name="store1"}
margins= {
{ name="Cessation", at={{var="Quit" value="1"}}}
{ name="No Cessation",at={{var="Quit" value="0"}}}
}
differences = {
{ label="Cessation Difference"
refMargin="No Cessation"
evtMargin="Cessation"}
};
run;
quit;
Predictive margins
Assuming the proper causal assumptions, the predictive margins computed using the training data would correspond to potential outcome mean estimates. Their difference would provide an estimate for the average treatment effect (ATE). To estimate a conditional effect within some subpopulation, a data table other than the training data can be used to compute the predictive margins. In general, you can use the bartScoreMargin action to score predictive margins that intervene on more than one variable. The predictions can be computed for an input data table other than the training data.
Figure 1 shows the predictive margin estimates, their difference, and 95% equal tail credible intervals for this example. The difference estimate of about 2.92 kilograms is comparable to the ATE estimates obtained in the PROC CAUSALTRT documentation. Note if you were interested in a function of the predictive margins other than their difference, you could use the casOut parameter to create an output data table on the server. It contains the predictive margin estimate from each sample of the ensemble saved for prediction. You can then apply the function of interest to this output data table and compute the corresponding credible interval.
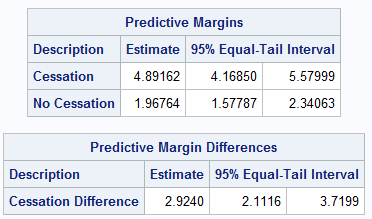
Figure 1: Quit predictive margins difference.
Bayesian Additive Regression Trees summary
With the new BART procedure and bart action set in SAS Visual Statistics, you can fit and save BART models for normally distributed response variables. By using a sum-of-trees ensemble, BART models provide a flexible approach. They can incorporate continuous predictors, categorical predictors, missing predictor values, and predictor interactions. Because the default settings for the BART prior tend to perform well, BART models are easy to fit. And they typically do not require any hyperparameter tuning.
With a saved model you can score new data or use the bartScoreMargin action to compute predictive margins to study the effect of intervening on one or more predictor variables in a population of interest. Although scoring data using a BART model requires more computational effort compared to scoring data by using other tree-based models, a benefit of using BART models is that you can assess uncertainty in the model predictions on the basis of variability in the posterior samples.
Michael Lamm is Senior Research Statistician Developer at SAS Advanced Analytics R&D.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht