

We are all hungry for data. Not just more data, also new types of data so that we can best understand our products, customers, and markets. We are looking for real-time insight on the newest available data in all shapes and sizes, structured and unstructured. We want to embrace the new generation of business and technical professionals with a true passion for data and for new technology that reshapes how data engages with our lives.
I can give a personal example of what I mean. Just about two years ago data saved my friend’s daughter’s life. At birth, she was diagnosed with seven heart defects. Because of new technologies like 3D interactive, virtual modeling, smarter EKG analysis, modern patient bed monitoring solutions, and other data-driven improved medical procedures, she survived two open-heart surgeries and is living a healthy life today. Data saved her life. That is what keeps me motivated each and every day to find new innovations and ways to make data available as quickly as possible to those that need it most.
I’m proud to be part of the Cloudera Data Warehouse (CDW) on Cloudera Data Platform (CDP) team. CDP is built from the ground up as an Enterprise Data Cloud (EDC). An EDC is multifunctional for the ability to implement many use cases on one single platform. By using hybrid and multi-cloud deployments, CDP can live anywhere from bare metal to public and private clouds. As we adopt more cloud solutions in our central IT plan, we see that hybrid and multi-cloud is the new normal. However, most mix-and-match environments create gaps in management that create new risk in security, traceability and compliance. To address this, CDP has advanced security and controls to democratize data without risking failings to meet regulatory compliance and security policies.
CDW on CDP is a new service that enables you to create a self-service data warehouse for teams of Business Intelligence (BI) analysts. You can quickly provision a new data warehouse and share any data set with a specific team or department. Do you remember when you could provision a data warehouse on your own? Without infrastructure and platform teams getting involved? This was never possible. CDW fulfills this mission.
However, CDW makes several SQL engines available, and with more choice comes more opportunities for confusion. Let’s explore the SQL engines available in CDW on CDP and talk about which is the right SQL option for the right use case.
So many choices! Impala? Hive LLAP? Spark? What to use when? Let’s explore.
Impala SQL Engine
Impala is a popular open source, massively scalable MPP engine in Cloudera Distribution Hadoop (CDH) and CDP. Impala has earned market trust on low-latency highly interactive SQL Queries. Impala is very extensible, supporting not only Hadoop Distributed File System (HDFS) with Parquet, Optimized Row Columnar (ORC), JavaScript Object Notation (JSON), Avro, and Text formats as well as native support for Kudu, Microsoft Azure Data Lake Storage (ADLS) and Amazon Simple Storage Service (S3). Impala has strong security with either sentry or ranger and is known to be able to support 1000s of users with clusters of 100s of nodes on multi-petabyte sized data sets. Let’s take a brief look at the overall Impala architecture.
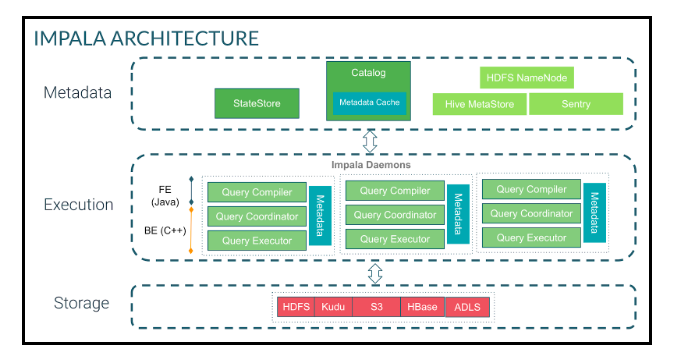
Impala uses StateStore to check on the health of the cluster. If an Impala node goes offline for any reason, StateStore informs all other nodes and the unreachable node is avoided. Impala catalog service manages metadata for all SQL statements to all the nodes in the cluster. StateStore and the catalog service communicate to the Hive MetaStore for block and file locations and then communicate metadata to the worker nodes. When a query request comes in, it goes to one of the many query coordinators where it is compiled and planning is initiated. Plan fragments are returned and the coordinator arranges execution. Intermediate results are streamed between Impala services and returned.
This architecture is ideally suited for when we need business intelligence data marts to have a low latency query response as typically found in exploratory ad-hoc, self-service, and discovery types of use cases. In this scenario, we have customers reporting sub-second to five-second response times on complex queries.
For Internet of Things (IoT) Data and related Use Cases, Impala, together with streaming solutions like NiFi, Kafka or Spark Streaming and appropriate Data Stores like Kudu, can provide an end-to-end pipeline latency of fewer than ten seconds. With native read/write on S3, ADLS, HDFS, Hive, HBase, and more, Impala is an excellent SQL engine to use when running a sub-1000 node cluster, with 100 trillion rows or more on a table or data sets of 50BP in size and beyond.
Hive LLAP
“Live Long And Process” or “Long Latency Analytics Processing”, also known as LLAP, is an execution engine under Hive that supports long-running processes by leveraging the same resources for caching and processing. This execution engine gives us very low latency SQL response as we have no spin-up time for resources.
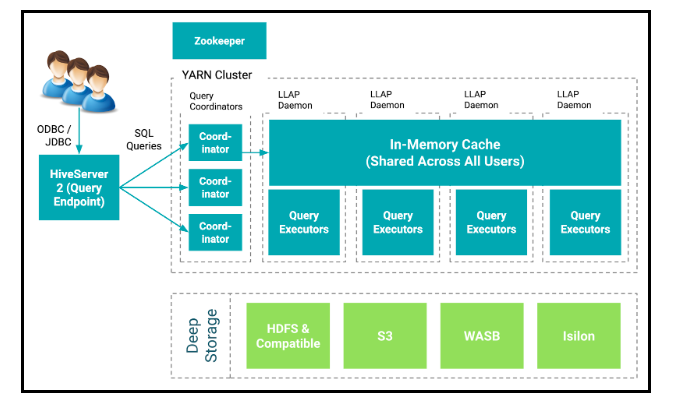
On top of this, LLAP respects and enforces the security policies – so it is completely transparent to the user that it is there – helping Hive workloads performance rival even the most popular traditional data warehouse environments today.
Hive LLAP offers the most mature SQL engine in the big data ecosystem. Hive LLAP is built for big data, giving users a highly scalable Enterprise Data Warehouse (EDW) that supports heavy transformation, long running queries, or brute-force style SQL (with hundreds of joins). Hive supports materialized views, surrogate keys, and constraints to give an SQL experience similar to traditional relational systems, including built-in caching for query results and query data. Hive LLAP can reduce the load of repetitive queries to offer sub-second response times. Hive LLAP can support federated queries on HDFS and object stores, as well as streaming and Real-Time by working with Kafka and Druid.
Therefore, Hive LLAP is ideally suited as an Enterprise Data Warehouse (EDW) solution, where we will encounter many long running queries that require heavy transformations, or multiple joins between tables on massive data sets. With the caching technology included in Hive LLAP, we have customers that are able to join 330 billion records with 92 billion records with or without a partition key and return results in seconds.
Spark SQL
Spark is a general purpose, highly-performant data engine designed to support distributed data processing and is suitable for a wide range of use cases. There are many Spark libraries for data science and machine learning which supports a higher-level programming model to speed development. On top of Spark are Spark SQL, MLlib, Spark Streaming and GraphX.
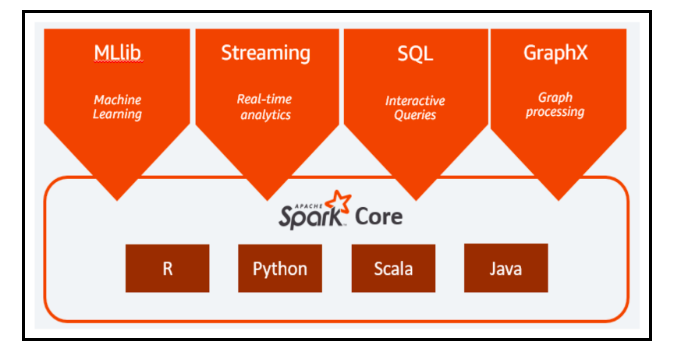
Spark SQL is a module for structured data processing, compatible with a variety of data sources, native with Hive, Avro, Parquet, ORC, JSON and JDBC. Spark SQL is efficient on semi-structured data sets and natively integrated with the Hive MetaStore and NoSQL stores like HBase. Spark is often used with a good mix of programming APIs in our favorite languages like Java, Python, R, and Scala.
Spark is very useful when you need to embed SQL queries together with Spark programs in data engineering workloads. We have many users in Global 100 enterprises running Spark for reducing overall processing on streaming data workloads. Combining this with MLlib, we see many customers favoring Spark for machine learning on data warehouse applications. With high performance, low latency, and excellent 3rd party tool integration, Spark SQL gives the best environment for switching between programming and SQL.
So, what is the right SQL Engine to use?
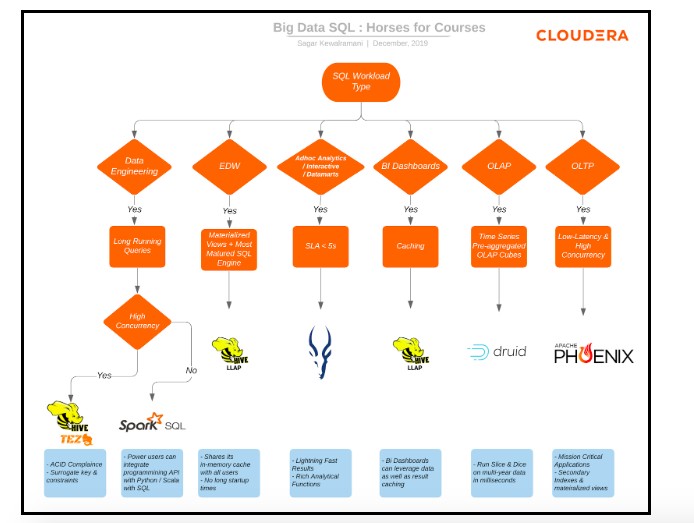
Since you can mix and match on the same data in CDW on CDP, you can select the right engine for each workload based on workload type, like data engineering, traditional EDW, ad hoc analytics, BI dashboards, Online Analytical Processing (OLAP) or Online Transaction Processing (OLTP). This chart below gives some guidelines for which engines and technologies are a good fit for each purpose.
Summary
If you are running an EDW supporting BI dashboards, Hive LLAP will give you the best results. When you need ad-hoc, self-service and exploratory data marts, look at the advantages of Impala. If you are looking at Data Engineering with long running queries without high concurrency, Spark SQL is a great choice. If high concurrency support is needed, you can look at Hive on Tez. For support for OLAP, with time-series data, look to add Druid to the mix, and if you’re looking at OLTP with a need for low latency with high concurrency, look to add Phoenix to the mix.
Bottom line – there are many SQL engines in CDW on CDP, and this is on purpose. Offering choice is the ultimate way to optimize for high-scale high-concurrency on massive data volumes without compromise. CDW on CDP allows for a common data context and shared data experience with a single security, governance, traceability, and metadata layer that allows for mix-and-match SQL engines on optimized storages. This gives you the freedom to use the best SQL engine, optimized for your workloads.
Sagar Kewalramani is Solutions Engineer at Cloudera.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht