

Op dit moment praat iedereen over Big Data, maar eerlijk gezegd verwacht ik dat dit over een paar jaar niet meer het geval zal zijn. De term "Big Data" staat al niet meer op Gartner's nieuwe "hype cycle" (2015 Hype Cycle for Advanced Analytics and Data Science). Dit wil niet zeggen dat de ontwikkelingen die nu plaatsvinden niet superbelangrijk zijn! Voor bedrijven, maar ook voor de burger, werknemer en consument gaat veel veranderen! Data Science is de naam van het bredere vakgebied dat dit allemaal mogelijk maakt. We praten ook niet over "grote computers", maar wel over Informatica (of IT) als vakgebied. Data Science is "here to stay" en bedrijven die hier niet op inspelen zullen ophouden te bestaan. Het gaat echter niet om het creëren van een hype die valse verwachtingen wekt. Het gaat erom dat bedrijven in staat zijn de grote hoeveelheden data om te zetten in echte waarde. Omdat het werk van managers, auditors, onderwijzers, en talloze andere beroepsgroepen veel meer data-gedreven en analytisch van aard wordt, moet een goede opleiding centraal staan.
Welke opleidingen zijn er op het gebied van Data Science?
Veel universiteiten bieden op dit moment al Data Science varianten aan van hun bestaande opleidingen. De situatie is vergelijkbaar met het begin van de jaren 80 toen zelfstandige Informatica-opleidingen uit Wiskunde-opleidingen voortkwamen. Eerst waren het afstudeervarianten, daarna pas echte opleidingen. Ik was zelf één van de eerste Informatica-hoogleraren die ook echt zelf Informatica gestudeerd had. Mijn voorgangers hadden Wiskunde, Natuurkunde, of Electrotechniek gestudeerd. Edsger Dijkstra, Neerlands bekendste informaticus, studeerde bijvoorbeeld Natuurkunde en Wiskunde. Ik zie veel parallellen tussen het ontstaan van Informatica toen en Data Science nu. Informatica kwam op vanwege de snel groeiende beschikbaarheid van computers. Data Science komt nu op vanwege de spectaculaire hoeveelheden (Big) data die overal geregistreerd worden. De Technische Universiteit Eindhoven (TU/e) loopt voorop op het gebied van Data Science opleidingen. Er zijn al twee Master-opleidingen: een Europese Data Science Master waarvan we trekker zijn en een "gewone" opleiding gericht op de Nederlandse studenten. In 2016 starten we met Tilburg ook een brede Data Science Bachelor en een Master opleiding in Den Bosch gericht op Data Science entrepreneurs. Eindhoven heeft een voortrekkersrol vanwege het Data Science Center Eindhoven (DSC/e) waarin 28 onderzoeksgroepen participeren en er veel samenwerking is met de industrie. Denk bijvoorbeeld aan het Data Science Flagship met Philips waarin 18 promovendi full-time werkzaam zijn.
Wat zijn de centrale vragen op dit gebied?
De term "Data Science" werd 45 jaar geleden al gebruikt door Turing-award winner Peter Naur. Het is dus goed om Data Science en Big Data in historisch perspectief te zien. Het gaat niet om één ding, maar om een breed vakgebied dat zijn wortels heeft in de statistiek, databases, visualisatie, algoritmiek, etc. Vanuit DSC/e hebben we onlangs de volgende vijf essentiële Data Science vragen geformuleerd:
Deze vragen zijn vrij fundamenteel van aard, maar de antwoorden zijn direct toepasbaar en zullen een enorme impact hebben op grote delen van onze maatschappij.
Wat is Process Mining en waarom is het belangrijk voor Big Data/Data Science?
Process Mining slaat een brug tussen data en processen. Het is de ontbrekende schakel tussen Business Intelligence (BI) en Business Process Management (BPM). Het probleem is dat op dit moment Big Data initiatieven zich richten op grote volumes en minder op de vraag welke vragen nu eigenlijk beantwoord moeten worden. Uiteindelijk gaat het niet op data maar om producten en diensten. Hiervoor zijn goede processen nodig. Een klant die niet binnen twee dagen antwoord krijgt, zal het worst wezen welke data beschikbaar is. Een apparaat dat na een week al kapot gaat wordt niet beter door meer data te verzamelen. Klassieke data mining technieken zijn niet in staat processen te analyseren: hun inzet is vaak beperkt tot een enkele stap in het proces. De meest tot de verbeelding sprekende vorm van Process Mining is "process discovery": het automatisch afleiden van procesmodellen (bijvoorbeeld een Petri-net of BPMN schema) uit event data. Dit is echter slechts één van de vele mogelijke analyses. Process Mining omvat het hele spectrum van analysetechnieken waar events direct gekoppeld worden aan activiteiten in een processchema. Ook het ontdekken van knelpunten en afwijkingen, het kwantificeren van complince op basis van echte data, en het voorspellen van doorlooptijden behoren tot het Process Mining spectrum. Problemen met betrekking tot performance en compliance kunnen direct aangepakt worden.
Big Data gaat vaak over operationele processen die in wekelijkheid plaatsvinden, maar klassieke analysetechnieken kunnen deze data niet omzetten in procesmodellen die knelpunten en compliance problemen laten zien. Process Mining is dus een essentieel gereedschap voor Data Scientist!
Welke Process Mining tools zijn er beschikbaar?
Voorbeelden van commerciële gereedschappen die Process Mining ondersteunen zijn Disco (Fluxicon), Perceptive Process Mining (eerder Futura Reflect), Celonis, ARIS Process Performance Manager (Software AG), QPR ProcessAnalyzer, Interstage Process Discovery (Fujitsu), Discovery Analyst (StereoLOGIC), en XMAnalyzer (XMPro). Deze zijn eenvoudig te bedienen: vergelijkbaar met het maken van een spreadsheet met Excel. Het open-source gereedschap ProM (www.processmining.org) is de de-facto standaard op het gebied van Process Mining in de wetenschappelijke wereld. Onderzoeksgroepen in Nederland, Duitsland, Estland, Frankrijk, China, Spanje, Italië, Portugal, Korea, Rusland, Amerika en Australië hebben plug-ins voor ProM ontwikkeld. ProM is voor iedereen beschikbaar, gratis, en biedt in vergelijking met commerciële gereedschappen enorm veel functionaliteit. ProM is echter wel lastiger te bedienen vanwege de uitgebreide functionaliteit. Kortom, er zijn verschillende instapniveaus.
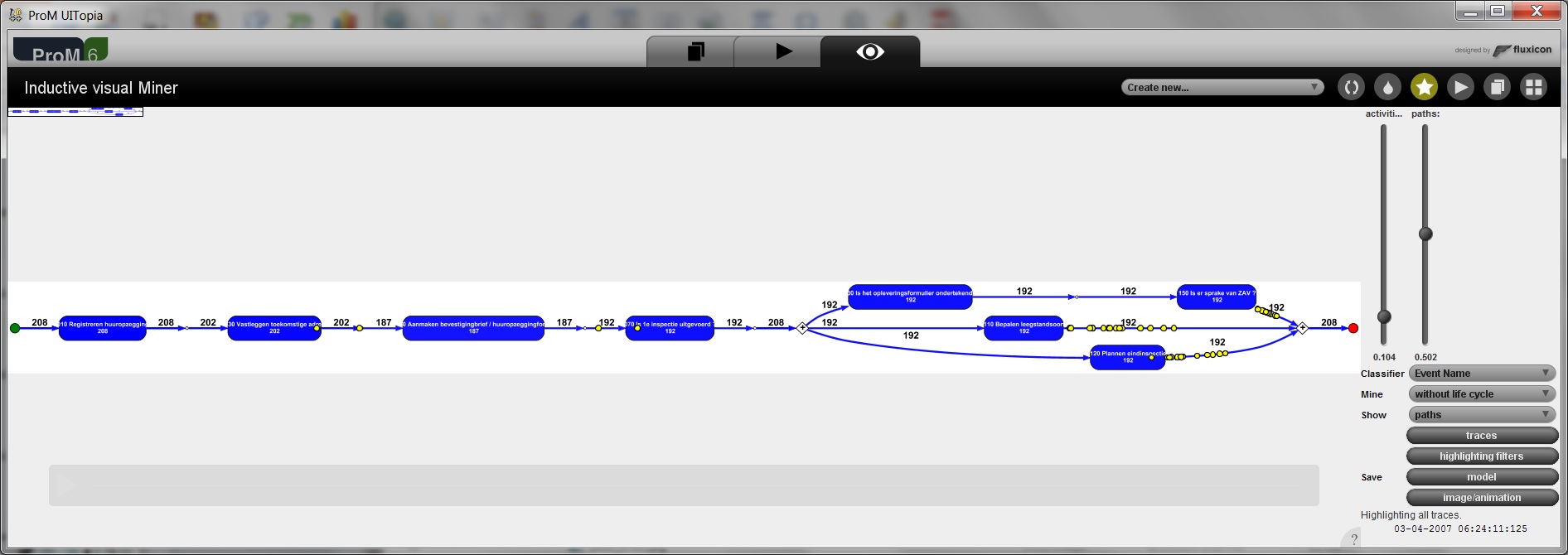
Gereedschappen als Disco kunnen direct CSV files inlezen en omzetten in het standaard formaat XES (eXtendible Event Stream) dat gelezen kan worden door onder andere ProM. Dit maakt na een eerste analyse met Disco, verdiepende analyses met ProM mogelijk (bijvoorbeeld compliance checking of het analyseren van procesveranderingen).
Hoe kan ik met Process Mining aan de slag?
Zoals aangeven zijn er diverse tools beschikbaar. Natuurlijk zijn ook data nodig. Uitgangspunt voor Process Mining zijn de zogenaamde event logs waarin events worden beschreven door de case waartoe ze behoren (bijvoorbeeld een ordernummer), de naam van de bijbehorende activiteit, een tijdstempel, en een willekeurig aantal aanvullende attributen (bijvoorbeeld de naam van de klant of de waarde van de order). Praktisch gesproken is het voldoende om een CSV of Excel file met drie kolommen te hebben: case (klantnummer, bestelnummer, patiëntnummer, enz.), activiteitnaam, en tijdstip. Men kan dan meteen aan de slag gaan met Process Mining. Deze data zijn echt overall aanwezig, maar moeten natuurlijk wel gevonden worden. In een doorsnee ziekenhuis vinden we bijvoorbeeld meer dan 800 tabellen met patiënt-gerelateerde informatie. Er is dus selectie nodig en gegevens van verschillende tabellen of bronnen moeten vaak gecombineerd worden.
De drempel voor het toepassen van Process Mining ligt laag omdat er geen complexe infrastructuur nodig is. Men kan meteen aan de slag. De ervaring laat zien dat een eerste analyse altijd al verassende inzichten oplevert: knelpunten zitten op andere plaatsen dan verwacht en het aantal afwijkingen ligt vaak onverwacht hoog. Kortom, veel aanknopingspunten voor procesverbetering.
Ook al is Process Mining laagdrempelig, natuurlijk is enige training nuttig. Naast de eerdere genoemde universitaire opleidingen, kunnen professionals in korte tijd Process Mining onder de knie krijgen door de gratis Massive Open Online Course (MOOC) "Process Mining: Data Science in Action" te volgen. Reeds 68.000 personen van over de hele wereld hebben deelgenomen aan deze gratis cursus.
Hoe toegankelijk is Process Mining voor startende ondernemingen? Is hiervoor een grote investering nodig?
Deze vraag is eigenlijk al beantwoord. Er is geen speciale infrastructuur nodig, er is gratis software beschikbaar, en de eisen ten aanzien van de data zijn beperkt. In vrijwel elke organisatie is Process Mining binnen een paar dagen nuttig inzetbaar. Wel is een "Data Science mindset" nodig. Een bekende uitspraak is "Big Data is als tienersex: iedereen praat erover maar niemand doet het". Voor startende ondernemingen zijn echte Big Data technologieën (die zaken als Hadoop en NoSQL-databases gebruiken) vaak een brug te ver. Gelukkig kan Process Mining ook prima in combinatie met relationele databases of eenvoudige log files ingezet worden. Wel zou ik startende ondernemingen adviseren te investeren in algemene Data Science skills: mensen moeten leren creatief en systematisch data om te zetten in waarde. Hierbij speelt Process Mining natuurlijk een cruciale rol.
Wil van der Aalst is één van de sprekers tijdens de Big Data Expo 2015 in de Jaarbeurs Utrecht.
Klik hier voor het programma.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht