

All organizations are affected by personal data protection regulations. Handling personal data in an optimal way requires organizations to strike the balance around four important factors around personal data: Classification, Categorization, Combination and Contextualization. The more of these four components can be addressed, and the more this can be addressed as a whole the more an organisation is able to streamline the process of handling personal data in an optimal fashion.
Where volumes of data have grown almost 50-fold over the last 12 years, so has the amount of data that is considered personal data. Personal data is any information that relates to an identified or identifiable living individual. Different pieces of information - when merged together - can lead to the identification of a particular person, do also constitute personal data. In the last 5 years we have seen many laws and regulations being put in place with the aim to (better) protect personal data. In May 2018 the European Union kicked off the General Data Protection Regulation (GDPR) aimed at the protection of personal data of EU citizens – inside and outside of the EU. Inspired by the GDPR, California issued the CCPA and CPRA, Brazil the LGPD, Japan the APPI and South Africa the POPIA.
All organizations are affected by these personal data protection regulations. International organizations have to deal with multiple regulations and laws, which do not always require the same handling of personal data, making it even more complex. Organizations in the public sector have – by default – a bigger share of personal data as these organizations are serving the public at large and therefore the need to be transparent, ethical and just in handling the data of citizens is even more important.
Handling personal data in an optimal way – so secure, value-driven, nimble – requires organizations to strike the balance around four important factors (the 4Cs) around personal data: Classification (what data is personal data?), Categorization (what privileges are required?), Combination (what is the impact of combining data?) and Contextualization (in what light are personal data handled?).
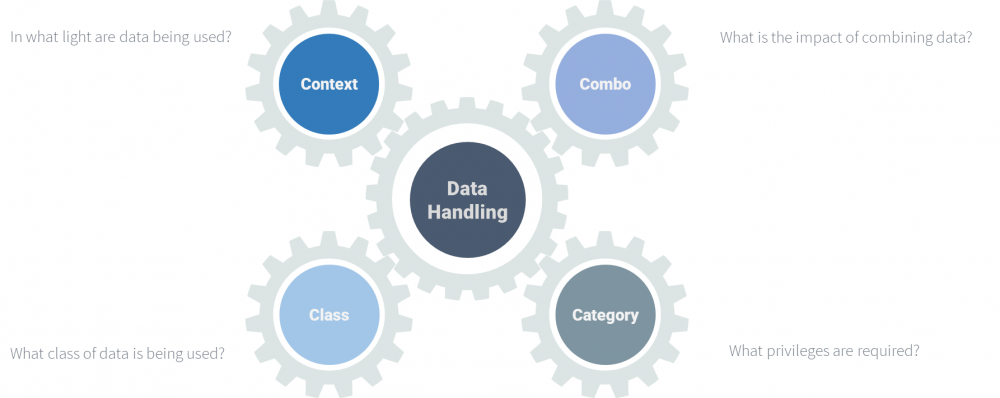
Figure 1: Connected 4Cs.
Where any change of any of the 4Cs potentially influences how the other Cs should work and – as a result – will also potentially require changes to the data handling to achieve an optimal state. In the next sections we will discuss each of the 4C’s separately, and conclude with a recommendations to find the elegance balance in an efficient way.
Classification
One of the challenges of handling personal data in the right way is to understand what is considered personal data, and what is not. Regulating bodies like the AP in the Netherlands, the CNIL in France or the ICO in the UK are not providing this information. There are no concrete lists of things considered personal data on their websites or in publications. At most there are some examples (i.e. name, address) and then off course there is the definition of personal data as already mentioned.
The distinction between personal data and non-personal data is relevant, as personal data needs to be handled more carefully and is to be secured better. Organizations have tried to address the identification of personal data by stating that what constitutes personal data is dependent on context. The case can indeed be made that looking at a set of data, that set contains either personal data – or not – depending on its composition. Stated differently: it is possible to determine on an entity level if the data set contains personal data.
Organizations that work this way have assigned the task of determining if an entity contains personal data to a role like that of the security officer. Bypassing the fact that security and privacy are quite different topics, it means that different people will make this decision for the data sets that they have been assigned to. There is nothing in place to guarantee that the decisions they make are consistent when looking at all the data sets. How could they be? There is no list of what data is considered personal data.
This process of determining what is and what is not personal data (on an entity or data set level) takes a lot of evaluation, its reusability is low (what is the effect of two or more additional attributes or the elimination of an attribute that was previously included?) and it’s hard to prove that the decision taken was the right one – at least in terms of consistency.
This is where technology can fulfill a key role: supporting staff to classify the data at the speed (new) data comes in and combinations of data, where artificial intelligence can be taught to identify personal data. Of course, such models need to be trained and the quality of such models regularly validated and improved. And most likely will never be perfect, but if they can correctly classify the bulk of data, be used consistently across the data value chain, and pass on the more difficult/doubtful data to security officers, this would already mean a significant improvement on the right handling of personal data. As a collateral benefit, such models could also help safeguard that no personal data leaves the ecosystem without being noticed.
Classifying data as personal data or non-personal data by way of making it a context dependent exercise on entity level (without the benefit of a personal data indicator) therefore seems less than optimal.
Categorization
After the classification has been done, there is the second step of categorization. Categorization is determining what level of access and security is needed to work with the data as different types of data need different treatment. Understanding if a data set contains personal data or if it contains sensitive data (i.e. financial or health data) is taken into account in determining if the data set is seen as public data (free for all), confidential or highly confidential.
Additional factors - like the origin of the data, or the lineage of data sets - can also be used as an important factor in determining the category that the data belongs to.
Categorizing data also bring the benefit of awareness, where the organization will not only be aware that they deal with sensitive data but also lead to handling data in an appropriate manner. In addition, categorization can also be used to retrospectively validate – by analyzing how data was used by whom – the effectiveness of categorization and its measures.
Combining data sets
Organizations that have classified and categorized their data typically next encounter the need to combine these categorized data sets in order to provide the business with the information and insights needed. But what to do if you need to combine for instance public data with confidential data? In the absence of any fine-grained decision criteria organizations choose to mark the highest (most stringent) level involved to the combined data sets. So in case public data and confidential data are combined, the combined data set is seen as confidential data. By choosing to give the highest category of the involved data set to the combined data set it becomes clear that this process will lead to all data being of the highest category. It is a simple (non-complex) process, but it leads to categorizing all involved data in the highest category. The risk in following this process is that non-sensitive and non-personal data is locked away from all people, except those with the highest clearance.
When combining data sets of the same category, the resulting data set would need to be examined for categorization as if it were a new data set. The combination of data might produce PII, and hence be eligible for a higher classification than the two source data sets. The same might be true for the classification. This underpins the need for a highly dynamic process of determining and applying the proper data handling principles.
Alternative approach.
Not all organizations have chosen the deliberate approach to classification, categorization and combination of data as described above.
While the approach described earlier only focusses on data sets, some organizations have looked at the lowest level of data: the attributes (grains of data, like name, address). On an attribute level it is quite possible to give an indication if the attribute in itself (in isolation) is personal data or not. One would need to look into the content of the data fields rather than the name of the field, as in some cases personal data is stored in non-obvious fields.
National identifiers like social security number, a name of a person or a mobile phone number are often seen as personal data. Other attributes like gender, monthly salary or age are seen as non-personal data as they cannot identify an individual. In between there is a category of data (attributes) that could be personal data (or not) based on the actual value. An example would be a text field (‘remark’ or ‘notes’). Depending on what was filled in this will constitute personal data or not.
Organizations that have placed a personal data indicator (which could be Yes, No, or Potentially) against the data attributes, have a list available that is used as an input instrument in the process of categorizing data. This list underpins the categorization process. To be clear: in putting together the personal data indicator list there will be discussions. Sometimes a name will be quite common (‘Smith’, ‘Jones’) and there can be a discussion if a national identifier in itself is personal data (how easy/difficult is it to point to a specific person if you have the identifier?). The big advantage of having a personal data indicator list is that you have a common starting point for classifying data. It also serves as a foundation to raise awareness inside the organization and have a common understanding on what attributes are personal data.
After concluding the discussion, and capturing the applied logic behind it, it becomes possible to categorize a data set with the common understanding which attributes determine the category of the entity. This is again true when combining data sets. You categorize the combined data sets based on the understanding which attributes lead to the category of the combined data set. Attributes that are part of the data set which have a lower category can still be made available, as long as the higher categorized attributes are not involved. This leads therefore to a more sophisticated approach and higher information availability.
Working with a personal data indicator list makes it possible to speed up (and automate) the process of classification, categorization and combination substantially. Having a human involved throughout the process is still a good idea and advisable. The reason for this is that you cannot automate all possible combinations of data (attributes) – nor should you. Even if you have automated large portions of these processes, you will regularly need to validate the quality of your algorithms. In such validation there is still no substitute for plain common sense. On the other hand: automating what and where you can, lead to a faster and more consistent process and frees up the human involvement for the parts where it truly makes sense.
Contextualization
Contextualization can be mentioned as fourth factor when discussing categorization, classification, and combination of data. Contextualization is about understanding the source and lineage of the data, but also about the intended and allowed use of the data. If the same data was part of an open data set or was produced by a third party it will probably be of relevance in how this data is seen and will be handled. Probably the access to the open data will be more relaxed than the data that originated from a third party.
The fact that the organisation has certain data does not mean that this data can be used for every possible application. Personal data is collected with a specific purpose in mind and its corresponding legal basis. The collection of the data needs to be grounded in one of the reasons for data collection as stated in GDPR. One of those reasons is ‘performance of contract’. Personal data is for instance needed to invoice customers for goods delivered. That does not mean that the organisation can include this personal data in a marketing campaign. Contextualization is the fourth C: after data has been classified, categorized and combined it is the contextualization that finally determines who has access to that data.
At every occurrence of using personal data the context has to be (re)validated. This means that this is also true during activities that are common in organizations, like sharing data between colleagues or departments, performing ad-hoc analysis with multiple data sets, or storing data for later use.
What can already be done?
For classifying data as either (potentially) personal data or non-personal data there are no lists available. This is something organizations need to do themselves, which is a good thing, and intended to be the case. Organizations who do this have added an indicator on the attribute level as part of their data dictionary, which is the logical overview of all attributes that the organisation uses. Vertical data lineage provides the link to the fields on a technical level.
Categorizing data (for instance using the CIA classification or Security Baseline) uses the personal data indicator list. The categorization is a decision tree that can be automated, depending on the exact logic used. If the logic also includes ‘sensitive data’ or other categories, it should be considered to add these as columns in the data dictionary and shared between users/systems of such data.
Determining the categorization of combined data can build on the personal data indicator list. For any combination of data, it can be determined if it is personal data (for instance: using k-anonymity, see also separate text). Feeding that into the categorization provides the category of the data set, supported by the categories of the underlying entities and the personal data indicators on the lowest level (attribute level).
Where data comes from (contextualization) is in most cases something that will be determined on an entity level, though for instance for master data records it could be necessary to define this on attribute level. For the different origins of data (data sources) characteristics on how to handle data can be defined. In most organizations it should already be known for what purpose data can be used, as this is an aspect that the Data Protection Officer (DPO) should have covered as part of the implementation of GDPR. Who then is granted privileges with respect to data is part of AIM and requires the ability to define access to data on an attribute level (both horizontal and vertical partitioning of data). It means that role-based access control (RBAC) is not good enough and attribute or policy-based access control (ABAC, PBAC) needs to be considered.
The more of these four components can be addressed, and the more this can be addressed as a whole (rather than stand-alone) the more an organisation is able to streamline the process of handling personal data in an optimal fashion: speed up the process and be consistent in handling personal data classification, categorization, combination and contextualization.
Some ideas for interesting topics:
• Influence of multi-language in complexity of identifying PII
• Influence of deviations of legislation between countries / EU in international organizations
• uUsing external reference data sets to determine whether data is PII (based on content rather than fieldname)
[Within the privacy domain the question has been raised if a data set containing only non-personal data can still be identifying, for instance if there are enough non-personal attributes or the values involved are unique? The answer to this question is that this indeed can be the case. There are a number of techniques that can be used to answer just this question. Among these techniques there is k-anonymity and l-diversity.]
This blog has been co-authored by Paul van der Linden (paul.vander.linden@capgemini.com) and Erwin Vorwerk (erwin.vorwerk@capgemini.com).


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
Deel dit bericht