

In our role as solution engineers at Tableau, we get hands-on with customers every day, and get to see how companies - big and small - use Tableau Prep to clean and prepare their data. From working with customers over the years, we hear, anecdotally, that cleaning data for analysis is a cumbersome process. The Harvard Business Review even found that many analysts spend 80% of their time preparing their data, spending only 20% of time for analysis. Tableau Prep shifts this paradigm by bringing self-service data preparation to everyone, rather than just those with specialized skills.
The Tableau Community is made up of smart, curious, data rock stars and we often get questions like, “Is Tableau Prep making a live connection to my data?” While that’s a relatively straightforward question to answer when we’re talking about Tableau Desktop, things work a little bit differently in Tableau Prep. Tableau Prep is equipped with three modes that work to make your flows as optimized and performant as possible, without bogging down your machine or underlying database. In this post, we'll get into the details of what is happening behind the scenes in Tableau Prep, so that you can navigate building and running flows with confidence.
Building your flow with Tableau Prep
When you are cleaning your data in any of the available step types (Clean, Union, Join, etc.), you are in what we call Interactive Mode in Tableau Prep. Interactive Mode delivers direct, interactive feedback as you clean, combine, and reshape your data. For example, if you join two tables together in a Join step, you will see the final join result—down to the number of rows—immediately.
At times, Tableau Prep may also sample your data. Sampling ensures responsiveness to keep you in the flow of your task, even when you are working with large amounts of data in Tableau Prep. You can use the default sample amount or build a sample set by specifying a fixed number of rows.
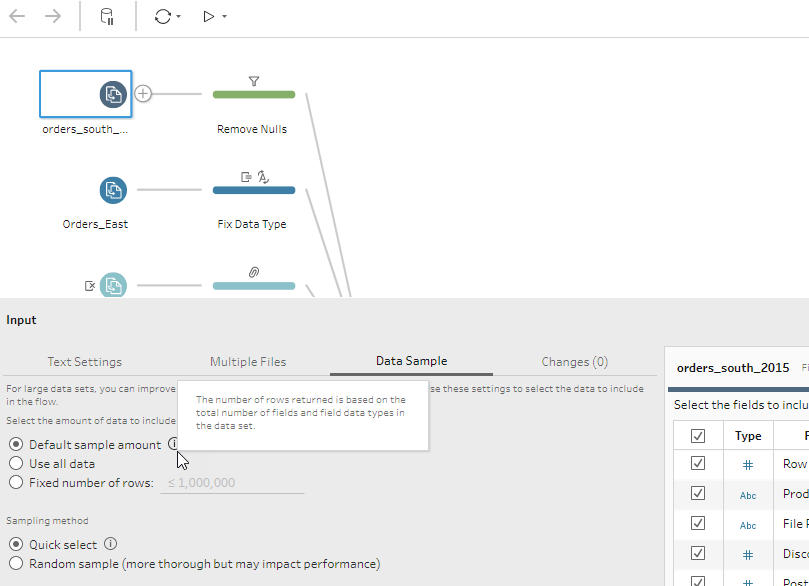
How Tableau Prep caches data
When you connect to a data source in Tableau Prep, you will notice that you don’t have the option to select between a live or extract connection like in Tableau Desktop. Tableau Prep instead caches your data as Hyper extracts in our high performance, in-memory data engine. Tableau Prep does not cache everything, however, and the experience differs if it is your first time building a flow from scratch, versus coming back to edit an existing flow already built by a colleague.
Building a flow from scratch
Tableau Prep will always cache the results from your Input step. In the Input step, Tableau Prep queries the input tables from the source database or files, ingesting data into a Hyper extract which serves as the cache used as you continue to build your flow. We create this cache so that you can validate your changes as they're happening without slowing down the underlying database or your machine. When you clean or reshape your data after the Input step, the changes are applied to the data in our cache. (Tableau Prep doesn't query the source tables after the Input step when you’re in Interactive Mode.) What is cached will be based on how you configure your Input step. If you choose to sample, remove columns, or change a data type, these changes will affect the result. Your data is cached again throughout the flow when you add computationally expensive steps like Join steps or Union steps.
Editing a flow
If you go back and edit a pre-built flow, caching will depend on which step you open and begin to explore. Tableau Prep is equipped with a special algorithm that decides which step is best to cache. Depending on where you are in the flow, and what data is necessary to deliver a performant, visual, and interactive experience, Tableau Prep may cache your Input, Union, or Join steps, among others.
What happens when you pause updates?
Sometimes when you are building a flow in Tableau Prep, you may not need direct, live updates. There are times when you just need to go in an add a quick cleaning operation or input data transformations in bulk. In these scenarios, Tableau Prep allows you to pause data updates. When you choose to pause data updates, you are in Metadata Mode. Pausing data updates allows you to quickly make changes to your flow before generating your results.
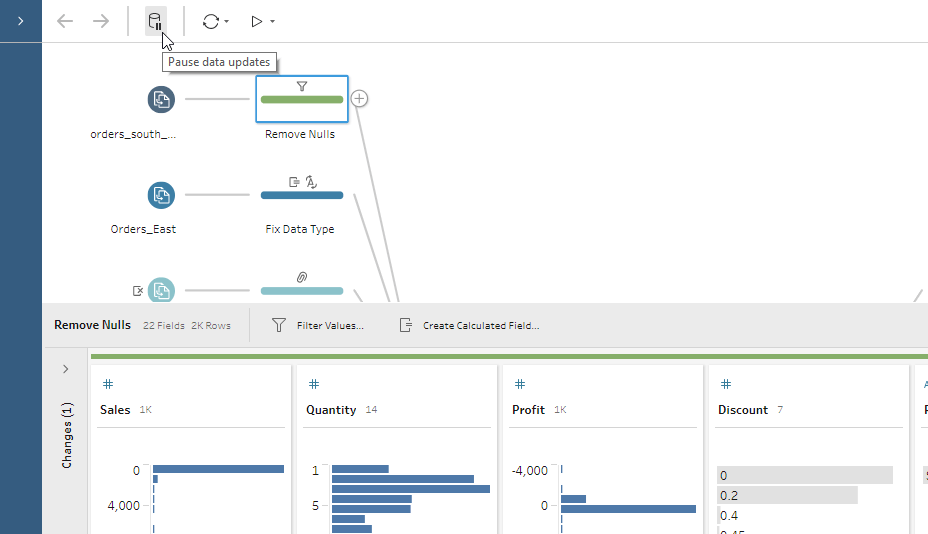
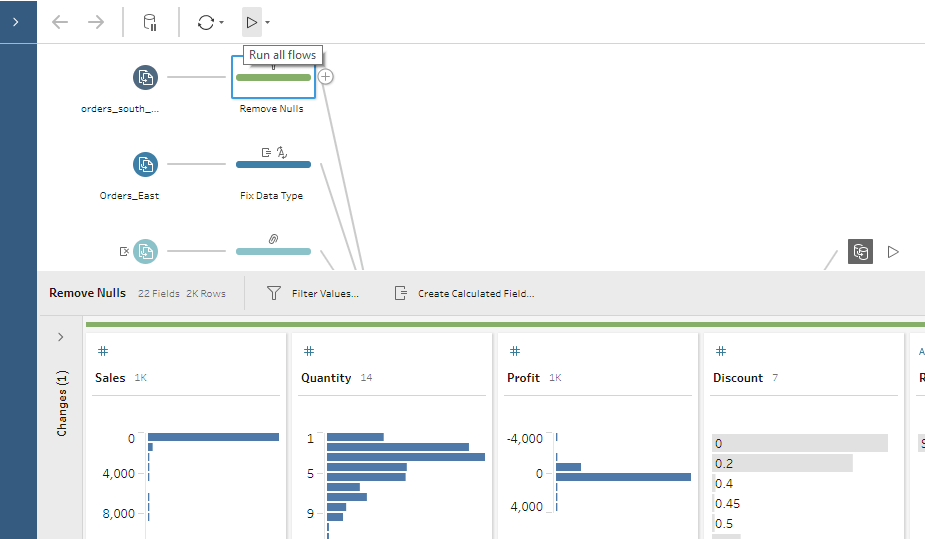
Running your flow with Tableau Prep
When you run your flow and generate your output for analysis, you are in Run Mode and Tableau Prep runs your flow against the entire data set. For example, if you set your sample size to five thousand rows, but your underlying data source has five million rows, the entire five-million-row data set is queried when you run your flow. Tableau Prep has a smart execution engine that pushes down operations to your database when possible. This saves you time and resources because Tableau Prep conserves your machine’s processing power if you’re running your flow manually or through our command line interface; if you are scheduling your flows on Prep Conductor, your Server resources are conserved in a similar way.
Did you know that you can create as many Output steps as you want in your flow? You have the flexibility to run one output at a time, or all outputs with the Run all Flows button at the top of the Tableau Prep interface.
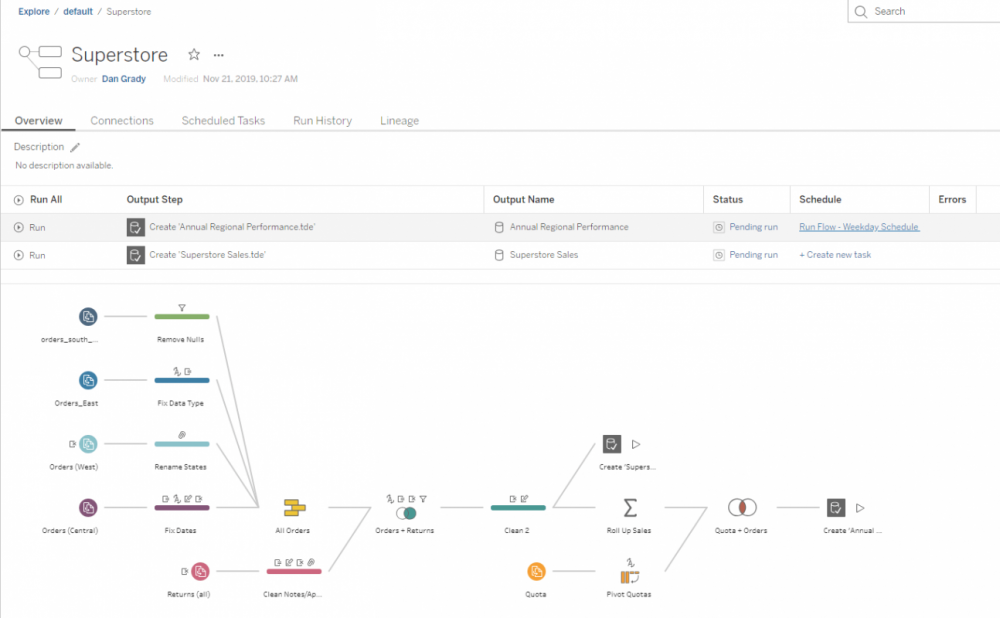
Manually running flows works well when just starting out, but ultimately, you’ll need to automate the refresh process to properly scale your data preparation flow to meet the needs of your entire organization. Tableau Prep Conductor, a part of the Data Management add-on, allows users to schedule and run workflows in a scalable, reliable, and secure fashion in a Tableau Server or Online environment. Prep Conductor (shown below) allows you to centralize the scheduling, monitoring, and administration of your flow.
Now that we have demystified how Tableau Prep works under the hood, you can build and run your data preparation flows with confidence.
Download a free trial of Tableau Prep.
Sasha Singh and Daniel Grady are working as Solution Engineer at Tableau.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht