

In this blog post, discover how unlabeled data - specifically in the scope of semi-supervised learning - can be used as a “hidden gem” in a variety of machine learning projects.
What Exactly Is Semi-Supervised Learning?
Let’s start at the beginning. Semi-supervised learning, as its name implies, falls between unsupervised learning (which has no labeled training data) and supervised learning (which exclusively has labeled training data). It uses both labeled and unlabeled samples to perform prediction. It can be used to improve model performance, particularly for smaller samples of labeled data.
When differentiating corporate web pages from personal ones, for example, it seems natural to consider a whole domain as personal if two or three of its pages have already been classified as personal. Attributing the same label to similar items can be seen in machine learning as “propagating” a label to neighboring samples. If the structure of unlabeled observation is consistent with the class structure, the class label can be propagated to the unlabeled observations of the training set.
Getting Started With Semi-Supervised Learning
A good place to jumpstart semi-supervised learning efforts is scikit-learn’s semi-supervised module, which implements two flavors of semi-supervised methods that perform label inference on unlabeled data using a graph-based approach. Label propagation computes a similarity matrix between samples and uses a KNN-based approach to propagate samples, while label spreading takes a similar approach but adds a regularization to be more robust to noise. We restricted our experiment to label spreading for optimal performance.
The underlying (supervised) model can also be used to directly perform the pseudo-labeling, which is also known as self-training. Our findings are supported by an experiment on textual data using the AGNews dataset.
Inside the Experiment
Many of you are probably curious if semi-supervised learning or self-training can actually improve model performance. We set out to answer these questions in the following experiment, starting with the simplest semi-supervised approaches. Therefore, we will not cover deep learning methods, adversarial methods, or data augmentation.
For our experiment, we will assume that the train dataset is partially labeled. The classical supervised approach will make use of only the labeled samples available, while the semi-supervised one will use the entire training set, with both labeled and unlabeled data.
At each iteration, we do the following:
• Fit an SSL-model on labeled and unlabeled train data and use it to pseudo-label part (or all) of the unlabeled data.
• Train a supervised model on both the labeled and pseudo-labeled data.
We also train a fully supervised model with no pseudo-labeled data at each iteration and refer to it as the base model. The training set size is given by the x-axis, while the y-axis is the model score. The confidence intervals are in the 10th and 90th percentile.
We used the AG News dataset for the experiment. AG News is a news classification task with four classes: world, sports, business, and science/technology. It has 150,000 samples. We performed our experiments on a subset of 10,000 samples. The text is preprocessed with GloVe embeddings.
Comparing Pseudo-Label Selection Methods
Similarly to other machine learning methods, semi-supervised algorithms may label samples with more or less confidence. Here, we consider two strategies:
• A fixed proportion of the dataset. We select the top n, with n = ratio * (number of labeled samples), according to the confidence scores. This method is referred to as “Ratio Pseudo Labels”.
• An absolute threshold on the labeling confidence. This method is denoted as “Selecting Pseudo Labels > Threshold” in the legend and mentioned as “uncertainty-based."
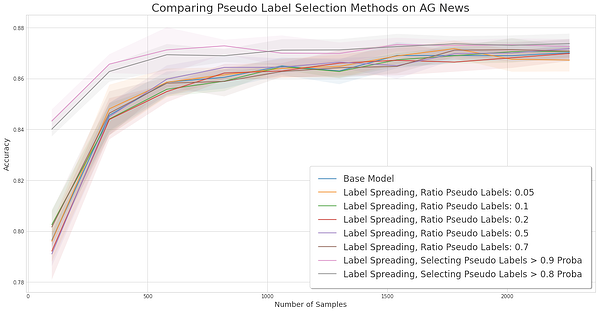
Experiment for comparing pseudo-label selection methods on the AG News dataset.
As you can see, uncertainty-based SSL is the only over-performing strategy. SSL is useful with a low number of samples which makes sense since once the dataset reaches a given size, the space of features has been explored and SSL can only confirm the prediction of the model.
In most cases, uncertainty-based SSL is equal or better than the base model. On AG News, the semi-supervised algorithms slightly underperform but the effect size is too small to draw a strong conclusion. Selecting pseudo labels based on a probability threshold rather than a simple ratio of true labels seems like the most performant method, and if it is not always performant, it rarely worsens the base classifier.
Self Training
Self-training, as mentioned in the introduction, consists of performing semi-supervised learning using the model itself as a pseudo-labeler. The idea behind it is to reinforce the beliefs of the models by iterating through the space of samples.
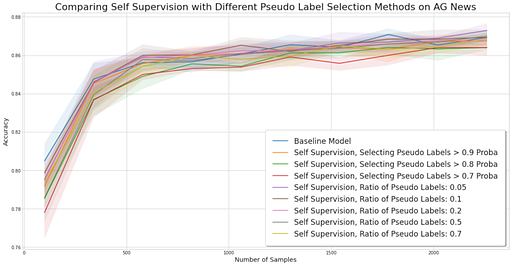
Experiment for comparing self-training methods on the AG News dataset.
In the experiments outlined here, we failed to obtain better performance using self-training. More recent works combine self-training and data augmentation — generations of samples similar to the labeled ones — in order to obtain better performance.
Semi-Supervised Learning Can Provide Value!
Semi-supervised learning techniques, which enable learning from partially labeled datasets, can help improve a base model if the right strategy is used to select the samples for pseudo labeling. Our experiment revealed that semi-supervised learning worked best on a smaller number of samples, indicating that it may be a fruitful tactic to employ at the start of a machine learning project.
We also observed that using a threshold on the confidence score estimated by the label spreading method prevents a loss of performance on datasets where semi-supervised learning underperforms. Using a threshold on the confidence score estimated by the label spreading method appears to be a good strategy. It also prevents a loss of performance on datasets on which SSL underperforms.
While labeling a significant amount of data can be costly, semi-supervised learning — when used properly — can help reduce costs and classify data as accurately as possible based on already labeled datasets.
Gaëlle Guillou

27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht