

A new decade comes with new perspectives. For companies striving to use data to drive innovation, the beginning of the new era is also a time to reflect on their data journey of the past decade, the various evolutions they've been through, and the new opportunities that await.
Whatever blueprint you have in mind for data and analytics, one agenda will remain on the roadmap – migration to the cloud.
However, data in the cloud can be extremely messy, and messy data provides no value until it’s cleaned up. According to our recent survey of over 600 data workers on the latest analytics and AI adoption in the cloud, while 76% of C-Suite executives have AI and ML initiatives in their company’s roadmap, 75% are not confident in the quality of their data. To get data ready for analytics on cloud, companies need to take into consideration both the characteristics of the data and the use cases they want to explore in a cloud environment, and select a data prep solution designed for the cloud as part of their modern analytics stack. In fact, choosing the right data prep solution is step 1 for any analytics success.
To address the demanding requirements for scaling, performance and management associated with the analytic projects on cloud, the architecture of a data prep solution is crucial. The modern solution, when compared with legacy desktop-only data prep tools, follows a fundamentally different design principle.
Let’s take a look at the key criteria of a properly architected cloud-native data prep solution and compare it with desktop data prep alternatives.
Integration with cloud services
A cloud-native data preparation solution should be tightly integrated with cloud services including storage, processing, security, and rich set of downstream analytics services to deliver elastic scalability, security, and cost benefits – key advantages of the cloud-for the entire data preparation workflow.
For example, a data preparation platform tightly integrated with the cloud should read from & publish data directly to the native storage services such as Amazon S3, or Microsoft Azure Data Lake Service. For job execution, a cloud-native data prep solution uses native processing engines such as Amazon EMR, or Azure Databricks, instead of a proprietary runtime engine to provide elastic scalability and flexibility to address the changing workload requirements. To effectively manage data access for all users, cloud data prep uses native security policies such as AWS IAM Role, or Azure Active Directory as opposed to a separate, dedicated security system.
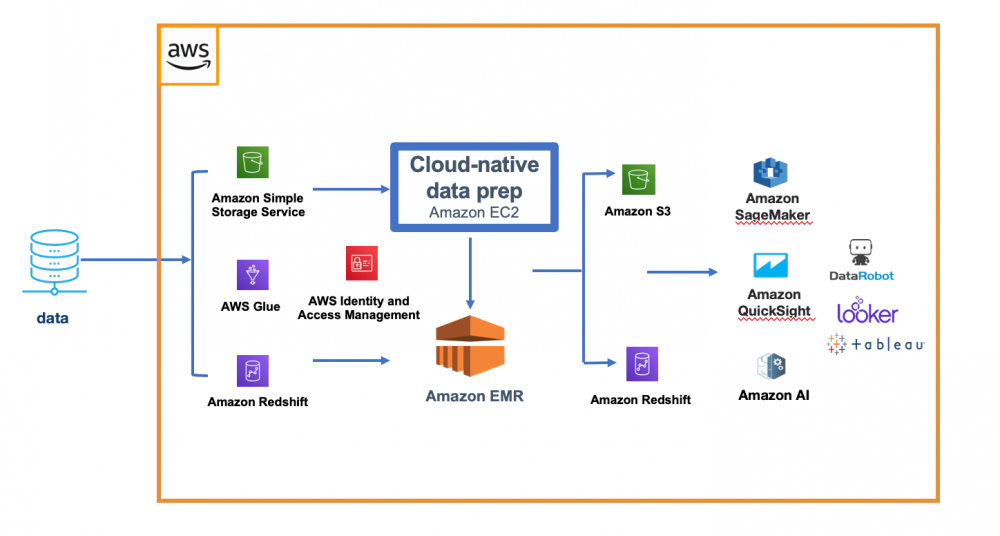
Fig 1. Example of cloud-native data prep architecture within the AWS ecosystem.
A desktop-only data prep tool is not integrated with cloud services and fails to scale as a result. A typical desktop data prep tool often takes a traditional client-server approach, with the desktop client deployed outside of the cloud(on-prem) handling departmental-level data prep jobs for a small number of users who require little collaboration. When dealing with enterprise-scale data prep projects on cloud, instead of leveraging the native cloud services to deliver elastic scalability and cost efficiency , the solution requires a number of proprietary, separate component systems to be deployed in the cloud to manage governance, job orchestration, execution and sharing. Such a disintegrated architecture breaks the scalability wall quickly when running large jobs, or a large amount of concurrent jobs within an enterprise environment. To overcome the scale limitation, users have to either over-provision every worker node to accommodate the largest possible workload, or add more infrastructure to meet the growing demand and performance requirements, both approaches drive up management complexity and cost.
Ah, did we mention the additional management hassle and cost for the on-going maintenance of the client machines?
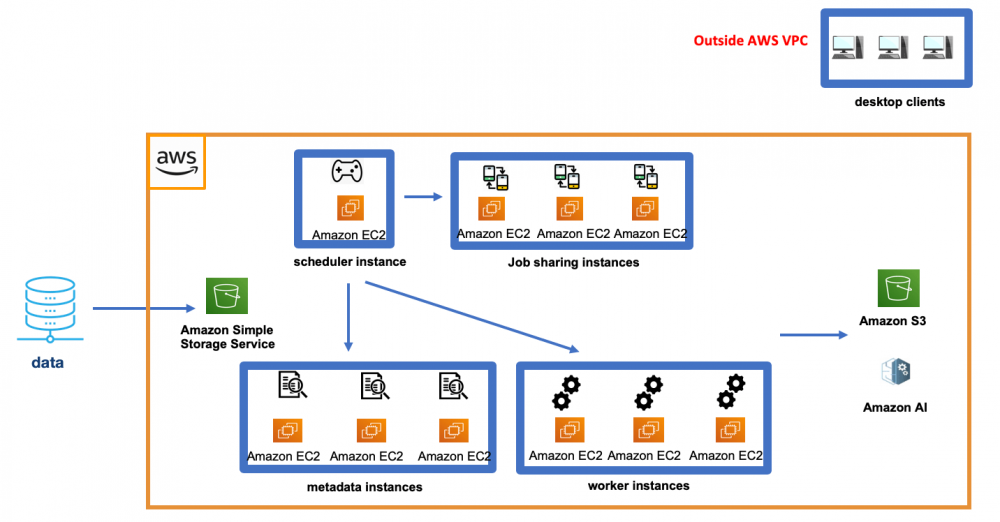
Fig 2. Example of a desktop-only data prep deployment in AWS with multiple EC2 instances.
User Experience
User experience is paramount when expanding your company’s analytics adoption in the cloud. With most data now stored in cloud data lakes and data warehouses, users with various skill sets now have easier access to the data without relying on IT to provision the data for them. After all, the user who understands the data best should be the one who prepares the data. A modern, cloud-native data prep solution empowers all types of users – technical or business users to easily wrangle the data in the cloud with an intuitive, modern data prep interface. Designed with human computer interaction principles at the core, the data prep solution allows users to visually profile, transform, and validate the data, while providing real-time feedback on data prep tasks for immediate response and risk mitigation. For example, users should be able to instantly preview the data when building up their recipe of transformations so they can spot outliers, unfamiliar patterns and other anomalies in their data immediately, and take the right course of action before the job completes to prevent undesirable outcomes. Such real-time feedback significantly accelerates the entire data prep cycle.
Desktop-only data prep solutions don’t provide such agility due to its legacy waterfall design approach. Whenever an error occurs during the data prep process, a user can’t easily identify the root cause of the issue because s/he doesn’t have the real-time visibility into the process. Instead, the user has to restart the entire process in order to scrutinize all the transformation steps. Such rigid design leads to longer analytics development cycles and delayed time to results.
Centralized, enterprise-class governance and collaboration
While a modern data prep solution should enable self-service for everyone in the organization, the same platform needs to provide centralized governance and orchestration for IT to ensure compliance and operational efficiency. For example, by leveraging the native security protocols and policies in the cloud such as AWS IAM Role and Azure Active Directory to manage data access, your organization avoids having to configure and maintain separate security solutions. To effectively manage the data prep workloads in production, a modern, holistic data prep solution should foster repeatable processes around job scheduling, publishing, sharing and monitoring while allowing customization, such as a user-defined job execution scheduling.
As mentioned previously, desktop-only data prep solutions are comprised of a number of disjointed component systems for managing job execution, governance and collaboration rather than on a single platform, each component will need a separate, dedicated instance in the cloud, driving up cost when running complex, cross-enterprise analytics use cases that require processing multiple jobs concurrently, and constant collaboration and job sharing.
Conclusion
A data prep solution designed for the cloud is a critical component of your modern analytics stack. With tight integration with the native cloud services, an interactive user experience, as well as enterprise-class, centralized governance and execution, a data prep solution architected for the cloud allows organizations to explore and run a wide range of analytics use cases at scale. Continuing to use desktop data prep tools that were adopted in the previous decade to wrangle data in the cloud will fail architecturally and slow down your analytics modernization journey.
Jie Wu is Director of Product Marketing at Trifacta.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht