

You could say nearly every business is suffering from the Midas Curse of the modern era. No, everything we touch isn’t turning into gold—it’s turning into data. Just look around. Every exposed surface of your organization is replete with information assets.
Wait, but isn’t this great news? At first glance, you may start counting your lucky stars when you find your data stores full to the brim. After all, in the modern era, data is extremely valuable. When data is aggregated across the business, combined and analyzed, decision makers can make better, more-informed decisions. The ability to use a vantage point capable of overseeing the entire data estate of your business and embedding it with AI is a key competitive differentiator for today’s market leaders.
But like King Midas cracking a tooth on his dinner turned to gold, too much of a good thing can prove an unexpected problem. The data reality for most organizations is sprawling, siloed and overflowing. How can business leaders possibly make data accessible, simple to leverage and trustworthy? The answer is IBM Cloud Pak for Data and data virtualization technology.
In this blog, I will highlight three primary challenges preventing you from making your data work for the business. We’ll identify one of the best-kept secrets of Cloud Pak for Data: new data virtualization technology that fully supports a multicloud environment, from IBM Cloud to vendors like Amazon.
Cloud Pak for Data is the key to unlocking your information assets
One of the key components of unlocking data is modernizing your data estate. This is the first in a prescriptive set of steps to making data work for the business, or the foundational platform on which the ladder to AI stands. Without a modern data platform, how will you make your collection of data simple, accessible – and ensure its quality, including accuracy, integrity and timeliness – regardless of what type and where data lives.
Like a 21st century gold rush, data scientists are analyzing their data for insights, but they have encountered some stumbling blocks. A few include:
- How do you know data fields and conventions in one source aligns with the fields and conventions in another area of the business?
- How do you translate cryptic data elements such as metadata to match their business context?
- How can you be sure that as you combine customer data you are not exposing personally-identifiable information (PII)?
What is most important is that you need to leverage AI to modernize your data estate. This builds consistency and sophistication into your data science and analytics process.
What often prevents this, however, boils down to three limiting factors:
1. Data Quality
2. Talent
3. Trust
Cloud Pak for Data with data virtualization is adept at solving for these limiters. Recently named by Forrester as a leader in Enterprise Insight Platforms, it’s lauded for its robust governance tools, machine learning-assisted data cataloging, and pre-integrated capabilities that allow clients to be productive in a week or less.
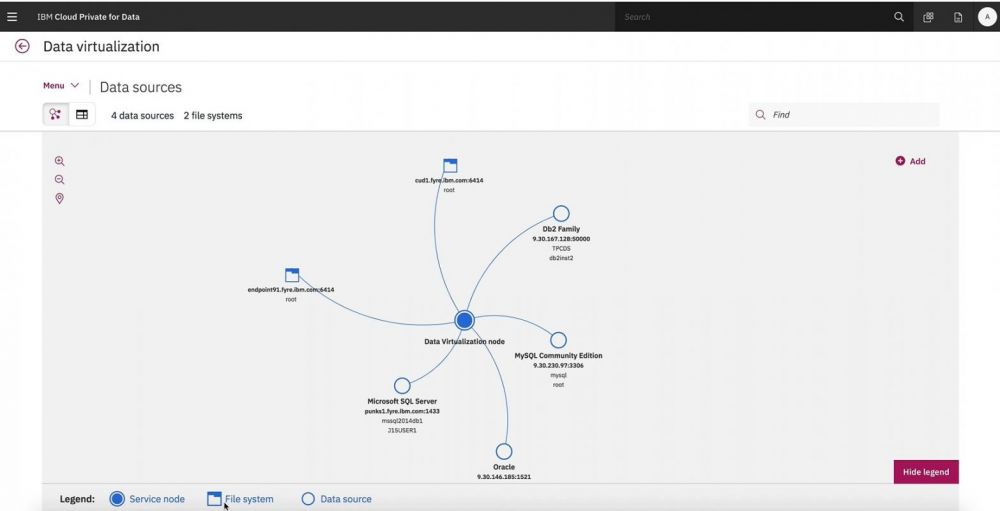
Demoing data virtualization in Cloud Pak for Data; manage all your data without moving it.
Three inhibitors solved by Data Virtualization
Data virtualization is an emerging approach to access, manipulate, combine, and query data—without needing to move it into a data warehouse, or needing to know any of the technical details about the data. In terms of the three major inhibitors to data science and AI outlined above, data virtualization provides some major relief:
Data quality. Data virtualization ensures your data stays where it is, lowering the risk of inconsistencies caused when manually manipulating, combining or moving data for query. A major strength is real-time/near-real-time accuracy, so only the latest data is fueling insights. With quality assured, data can be accessed simply and easily by data scientists.
Talent. Data virtualization lowers some skill barriers to accessing data, allowing more opportunities to communicate insights and permit more members of the team to create value. It also helps the highest-skilled data scientists to spend less time manually configuring data connectors to get right to work on value-added tasks such as analyzing data.
Trust. Data virtualization platforms have consistent built-in-patterns for accessing data, giving users the transparency to know where their data is coming from. Data is up-to-date, so regardless of how fluid it is or the number of different sources it is collected from, it can be trusted.
Climb the ladder to AI
AI is not magic. Neither is it a silver bullet to your problems or an overnight, miracle success. To succeed with AI, you must commit to a prescriptive approach that is anchored as a three-legged stool. You must apply a unified strategy of AI, data and cloud.
We think of AI as a journey or a ladder. But many organizations are not prepared to begin their ascent. Before you can start reaping the benefits of AI, you need to have a solid foundation; you need information architecture. There’s no AI without IA. But that doesn’t mean your IA needs to be inflexible. Your first step begins with modernizing your data estate using platforms such as Cloud Pak for Data with data virtualization—on any cloud you prefer. Learn more about eliminating data silos and data virtualization in Cloud Pak for Data by reading through this whitepaper.
Follow IBM clients throughout their journey to AI in our collection of client stories and learn who were among the first to confidently put AI to work in their industry.
Accelerate your journey to AI with a prescriptive approach. Visit ibm.com/data-ai to learn about how IBM’s ladder to AI helps you modernize, collect, organize, analyze and infuse all your data.
Thomas LaMonte is Content Marketing Director at IBM Data and AI.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht