

Business Intelligence is complex. Je hebt enerzijds te maken met snel veranderende informatiebehoeften. Anderzijds heb je te maken met verschillende bronsystemen en een vaak onvolledig zicht op de kwaliteit en beschikbaarheid van de data. Daarnaast zorgt nieuwe technologie voor nieuwe mogelijkheden, maar brengt de invoering daarvan weer nieuwe complexiteit met zich mee.
Scrum is een raamwerk dat gebruikt wordt om werk aan complexe producten te managen. Het is daardoor goed toepasbaar in een Business Intelligence omgeving. De grote kracht van Scrum zit hem in de eenvoud van het raamwerk, maar het succes is afhankelijk van een goede toepassing hiervan. Hoe pas je Scrum toe in een Business Intelligence omgeving? Wat zijn de valkuilen en de tips?
In deze serie blogposts deel ik mijn inzichten op dit gebied. Iedere blogpost gaat in op een bepaald onderwerp: van het opstellen van user story’s tot de rol van de product owner en van de manier waarop je plant tot de rol van architectuur. Waar mogelijk zal ik daarbij ingaan op de specifieke zaken waar je in een Business Intelligence omgeving tegenaan loopt. Deze eerste blog post gaat in op een manier waarop je de gevraagde functionaliteit kunt opdelen.
Sprint
Een sprint in Scrum is een timebox van maximaal een maand waarbinnen je een potentieel te releasen product incrementeel ontwikkelt. Sprints zorgen voor voorspelbaarheid en een tijdige inspectie en adaptie van je product. Het financieel risico wordt zo beperkt tot de lengte van de sprint. Dit risico wordt nog verder beperkt door ervoor te zorgen dat je tijdens de sprint meerdere onafhankelijke, kleine, brokken functionaliteit realiseert. Dit zorgt ervoor dat zelfs wanneer je niet alle items (vaak beschreven in user story’s) binnen een sprint voltooit, je toch functionaliteit levert. Maar hoe bepaal je de opdeling van deze user story’s?
In veel Business Intelligence projecten maakt men een onderscheid tussen front- en backend ontwikkeling. Het ontwerpen van een rapport is immers heel iets anders dan het ontsluiten, laden en transformeren van de data. De neiging bestaat dan ook om hiervoor aparte user story’s te definiëren. De functionaliteit wordt hiermee dan in twee of zelfs meerdere horizontale slices en user story’s opgedeeld. Een nadeel hiervan is dat er meerdere slices en user story’s nodig zijn om waarde te creëren. Een ontsloten en getransformeerde dataset waarvoor het bijbehorende rapport nog moet worden gebouwd, levert immers nog geen directe waarde op voor de organisatie.
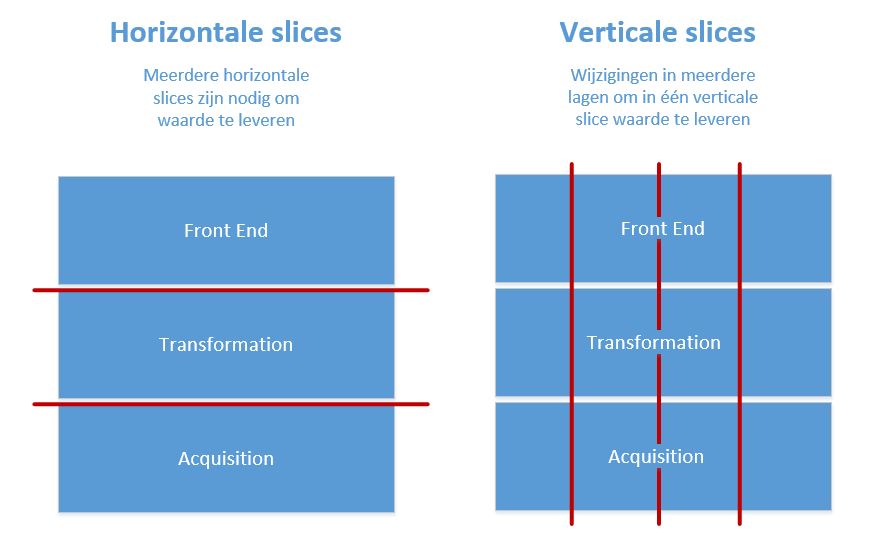
Het advies is dan ook om niet met horizontale slices, maar met verticale slices te werken. Daarin combineer je dan frontend ontwikkeling met backend ontwikkeling in het geval je ook nieuw data ontsluitingen of transformaties nodig hebt. Je hebt dan wel een Scrum team nodig dat beide disciplines (front- en backend ontwikkeling) beheerst. Daarnaast wordt het een extra uitdaging om je user story’s klein te houden, zodat je er nog steeds meerdere in een sprint kunt realiseren.
Dat vergt de nodige creativiteit. Twee Voorbeelden daarvan:
• Een user story waarin je een compleet dashboard oplevert, kun je bijvoorbeeld splitsen in meerdere user story’s, waarin je in de eerste user story slechts een simpel rapport met een grafiek oplevert. Maar dan wel inclusief de benodigde data-ontsluiting en transformaties wanneer deze nog niet bestaan.
• Voor een rapport met het aantal orders per klant, kun je in de user story alle klant- en ordergegevens ontsluiten. Maar voor het rapport zelf heb je wellicht niet al deze gegevens nodig. Probeer je dan ook te beperken tot wat je echt nodig hebt.
Nu zal je ten aanzien van voorbeeld twee wellicht denken dat het veel efficiënter is om in een keer alle order- en klantdetails te ontsluiten, en rework te voorkomen. Maar bedenk dan ook dat je al deze details moet modeleren, laden, testen en documenteren. Het niet meenemen van deze details kan inderdaad leiden tot rework, maar laten we eerlijk zijn: rework komt bijna altijd voor. Ook als je probeert dit te voorkomen en het in een keer goed te doen. Het is veel productiever om er vanuit te gaan dat rework plaats zal vinden en je omgeving daarop in te richten. Maar daarover meer in een volgende blogpost.
Betere feedback
Verticaal slicen zorgt voor user story’s die daadwerkelijk waarde leveren. Bij het bespreken en afstemmen van deze user story’s is er daardoor ook meer aandacht voor die waarde: wat is er wel, en wat is er niet nodig. Het zorgt ervoor dat je eerder, binnen een zo klein mogelijke user story, waarde levert. Verticaal slicen zorgt er ook voor dat er eerdere en betere feedback op je deliverable kan worden gegeven. Je levert immers iets wat te inspecteren is door een business gebruiker. En, zoals het Scrum framework beoogt, werkende software wordt daarmee de belangrijkste indicator van de voortgang.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht