

Throughout last year, we have been busy revamping the internals of the ArcGIS API for JavaScript to support larger feature data sets in 3D. In version 4.9 we have added support for displaying large point datasets, and in version 4.10 we extended this to large line and polygon datasets. As a result, there is no more a 2,000 feature limit when adding a feature layer to your scene
In this blog post you will learn about the technical details behind loading and displaying large datasets. We have included examples of 3D city visualizations to help further understand these topics. Following our approach you can create a 3D view of your city using only 2D data. Hundreds of thousands of buildings generated live from 2D polygons!
How does it work?
For feature services that have less than 2000 features (let’s call them small services) we can load all the data at once in the client. Internally, we call this snapshot mode, and we continue to use it for small services. This mode has the advantage of instantly showing all the features while navigating, since all the data is on the client and rendered directly.
Whenever a service exceeds the amount of data that can be handled in snapshot mode, we switch automatically to a tiled on-demand mode. This tiled mode behaves similar to SceneLayers, but without a cache. The tiled mode loads large services and organizes them in tiles. This mode can display up to 50.000 features in a single layer.
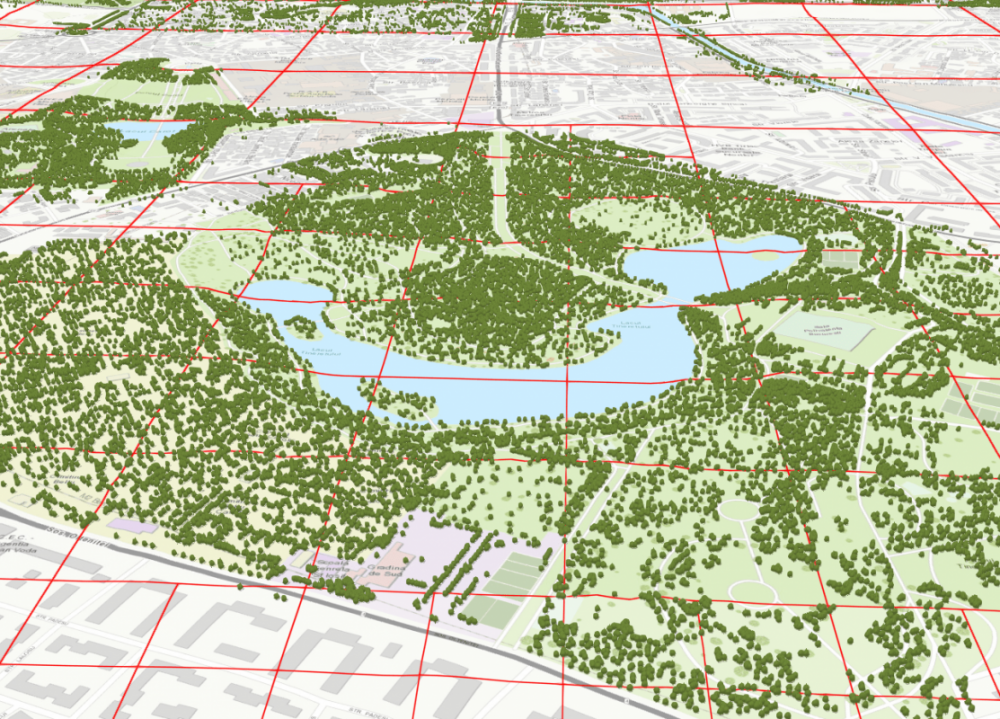
In this view the tiles are displayed with red outlines. A typical view contains 20 - 50 tiles.
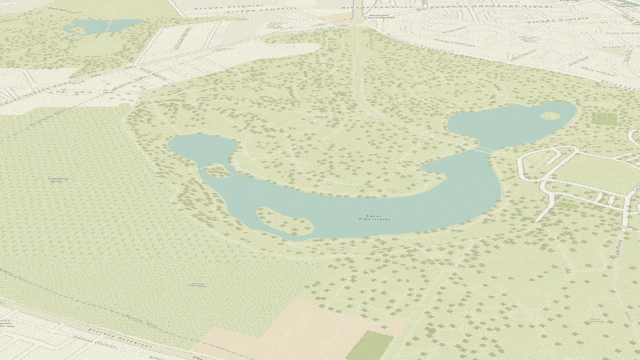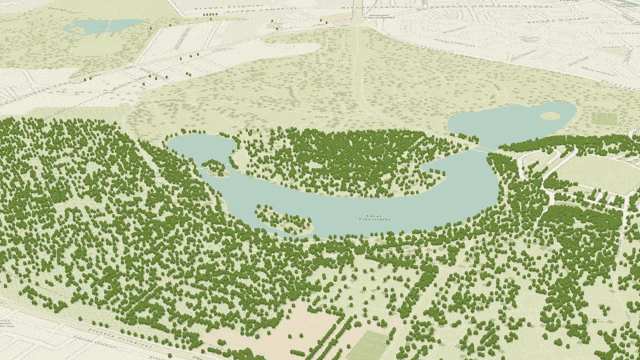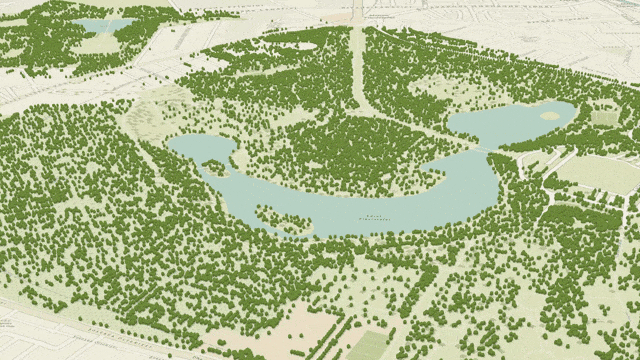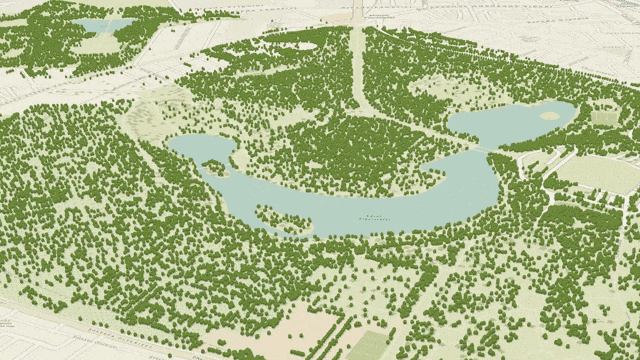
The tiles are loaded progressively, starting with closest tile.
We also use quantization, a technique that reduces the resolution of line and polygon features based on their size on screen. Quantization reduces the amount of data we need to handle, but may cause very small features to not be loaded since they get “quantized away”. You can also see quantization temporarily when zooming into a large feature layer, until we have updated the data with the finer quantization.
When we cannot load all the data in a tile, we now try to load a meaningful subset of the data:
First, we query how many features are in this tile, and then load the same percentage of all features on all tiles. This creates a fair subsampling of features across all tiles, which gives a good visual indication how the data is distributed spatially. It also makes tile border less visible.
Secondly, we use distance-based thinning for tilted views. This results in denser tiles closer to the viewer, and sparser tiles towards the horizon.
This new feature selection algorithm also results in faster load times. By using a precise count, we can better estimate how many features we need for each tile, and request more efficiently from the server. Additionally, when supported by the server, we request the features in a binary format (pbf) instead of JSON, which reduces the response size.
Large datasets in action: 3D city visualizations with 2D features
Most cities don’t have detailed 3D models of their buildings. This is also the case for the cities in Romania, so we decided to download all the building footprints available on OpenStreetMap and to visualize them in 3D. There are around 1 million mapped buildings for the whole country. To add a bit of freshness to the map we also downloaded all the trees. Before we dive into the workflow, here is what Bucharest looks like in the final map:
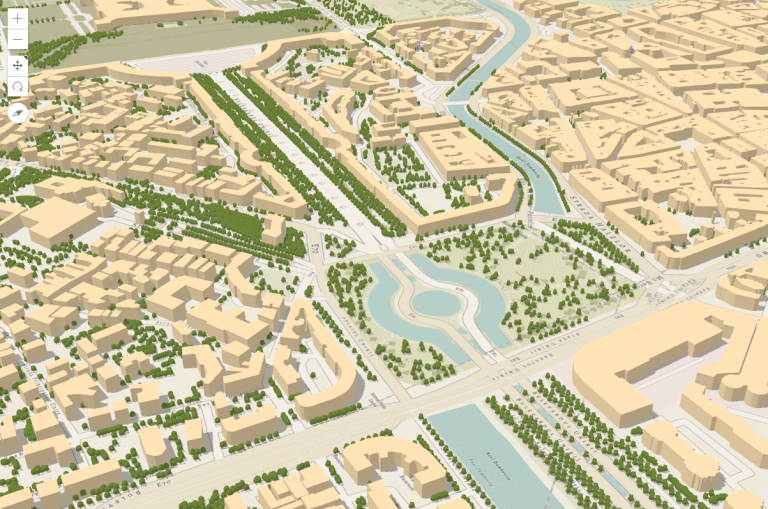
Bucharest, city center
Download and publish data
There are several ways to download data from OSM, you can read more about it on the OSM Wiki. When downloading data for a whole country, the easiest is to download it from Geofabrik. Some things to be aware of when using OSM data: you should credit OpenStreetMap and the end result should be redistributed under the same license (read more about it here).
Performance tips
Most of the OSM data comes in WGS84 and my web scene is in Web Mercator. When publishing large data sets, it’s important to have all the data in the same projection. Otherwise it will be reprojected on the server for each request, which in the case of large datasets is time demanding.
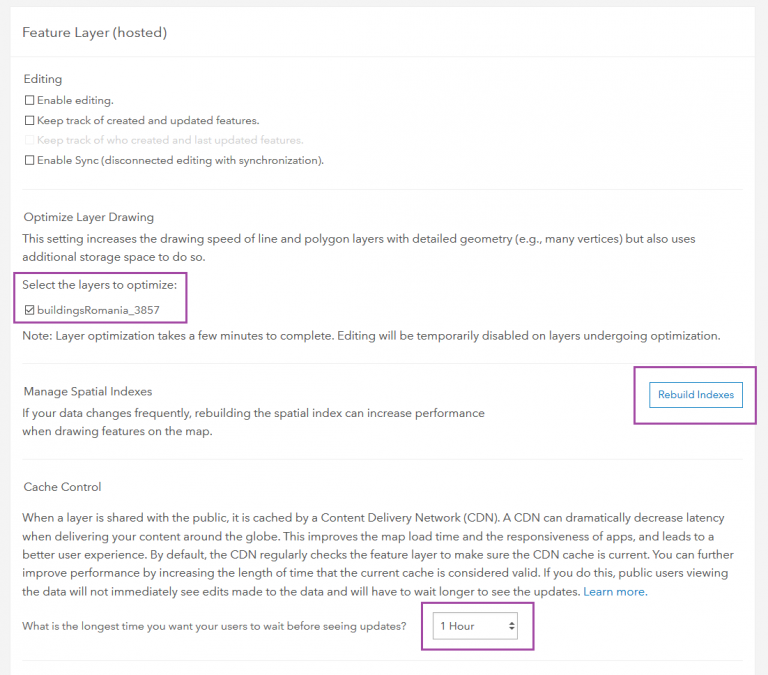
After the data is ready (don’t forget to add the attributions!), we can publish it to ArcGIS Online. Here are a few optimizations that we made in the item settings to make our layers perform better:
1. Tick the checkbox for Optimize Layer Drawings.
2. Rebuild Spatial Index.
3. Set the Cache Control to 1 hour.
Create visualization
Now it’s time to visualize the buildings. To write less code, we created the WebScene in the SceneViewer where we extruded the building footprints by 10 meters and we symbolized the trees with realistic 3D models. We saved the scene and loaded it in a custom application using the portalItem id. Then we added a menu at the bottom that zooms to the major cities based on the slides defined in the webscene. This is what the cities look like:
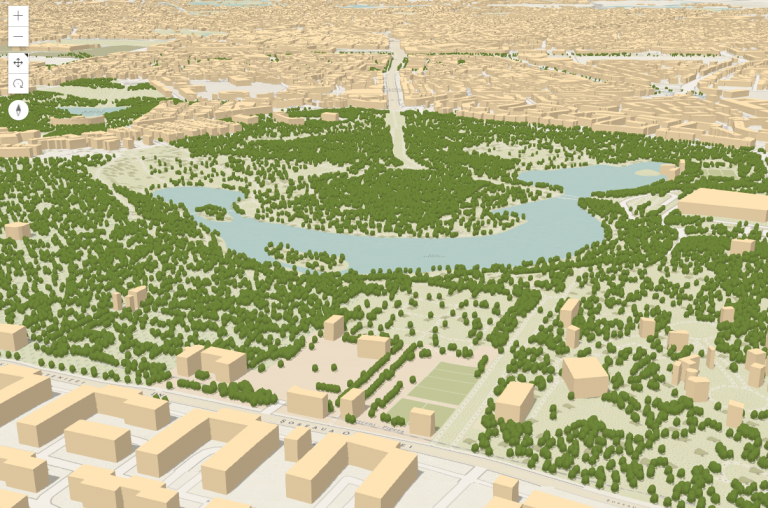
Park in Bucharest

Constanta, a port city at the Black Sea
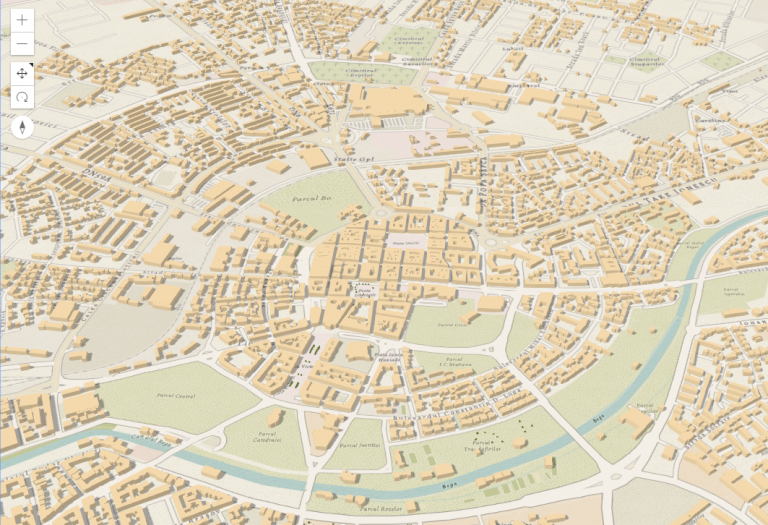
Timisoara
You can view the live app here.
This is basically how you can create a 3D view of your city using only 2D data. I used the data from OpenStreetMap, but some cities have Open Data Portals where you can find the building footprints (even with height information). This is the case for Paris, which published all the building footprints on the Paris Open Data portal. The footprints have height and construction period information so I used those attributes to represent the extrusion height and color. The extrusion height is set as a size visual variable, and construction periods are used as categories in an unique value renderer.
const renderer = {
type: "unique-value",
valueExpression: periodExpression,
uniqueValueInfos: [{
value: "Before 1850",
symbol: {
type: "polygon-3d",
symbolLayers: [{
type: "extrude",
material: {
color: "#6F2806"
},
edges: {
type: "solid",
color: [50, 50, 50, 0.5],
size: 1
}
}]
},
label: "Before 1850"
},
... // some more categories here
],
visualVariables: [{
type: "size",
field: "H_MED",
valueUnit: "meters"
}]
}
Here’s what the visualization looks like:
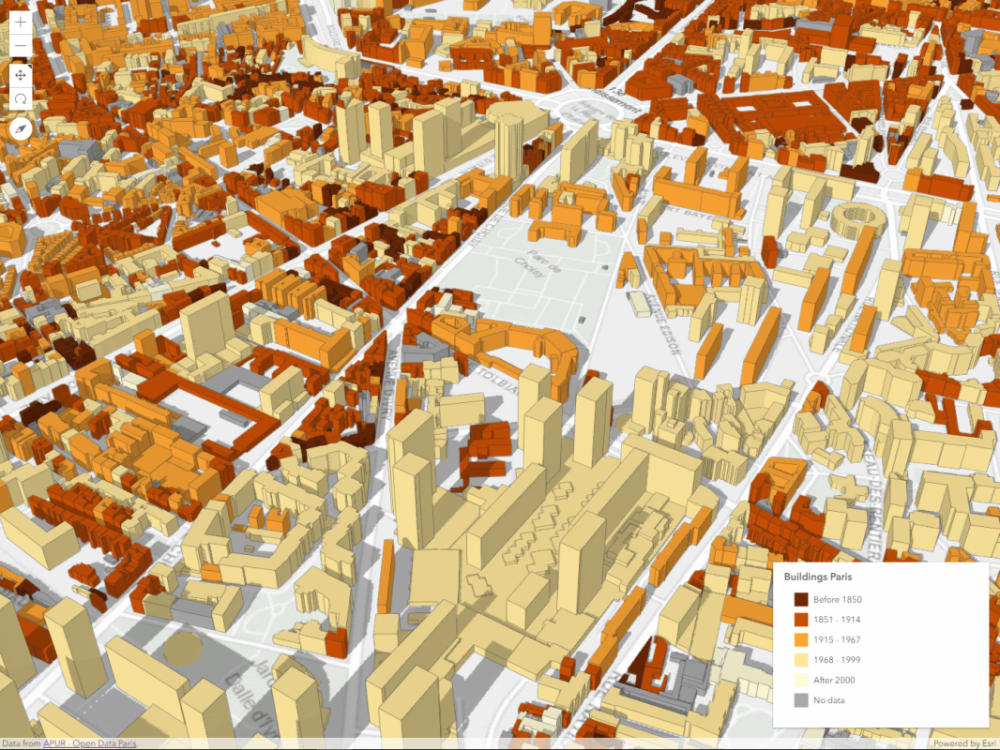
Extruded building footprints in Paris with height and construction period information.
Explore the buildings of Paris live! And you can view the code of the application here.
Raluca Nicola is a cartographer with a focus on 3D web cartography and works as a Product Engineer for ArcGIS API for JavaScript 3D.
Stefan Eilemann works as a software engineer in the ArcGIS JS API team.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht