

Experian’s Business Information Services (BIS) unit spent years building a valuable and unique database of corporate relationships to better serve customers. The unit created this database of corporate hierarchies using technology to do entity matching, and people who evaluated the matches and updated them based on research and human evaluation.
This process was time-consuming and limited the number of company hierarchies the team could evaluate and match. It maintained a subset of corporate hierarchies out of a full universe of companies available to them due to the intense manual effort required. Plus, because of how much human involvement was needed, they were limited on how often they could refresh the hierarchies.
The IBM Data Science Elite team had a simple mission: apply AI to learn what Experian has done over the years building corporate hierarchies and then apply that to the full universe of companies that they traditionally couldn’t evaluate. The goal was to increase the number of corporate hierarchies and increase the frequency of corporate hierarchy matching.
The results? AI and machine learning are now helping Experian solve a problem building and maintaining business families and corporate linkages with a potential 500 percent increase in coverage and 80 percent reduction in cost.
Our team began with a discovery workshop to understand the problem. This included digging into the data with an open discussion of the current process and what they would like it to be. This included a team of business experts from Experian, plus stakeholders who understood the value of a new solution and an IBM Data Scientist Elite who could help develop a new approach. After the workshop, we put together a plan which included leveraging machine learning. The plan was to train new machine learning models using Experian’s existing, validated hierarchies. Each hierarchy is a company with thousands of sub companies matched with years of Experian expertise, intellectual property and software.
We then documented our approach, defined some agile sprints and moved to project kickoff.
Next we needed a platform – something with key open source data science and machine learning libraries that would meet Experian’s strict guidelines on encryption and key management. It would have to scale with the horsepower needed for such a complex problem. We especially needed to use GPUs, and we needed something that was quick to get started.
With that in mind, we spun up a Watson Studio environment to perform our modeling; Watson Machine Learning for our model deployment and scoring; Object Storage for Data Storage and Key Protect for Data Encryption and Security. All components were spun up on IBM Cloud for the project.
We started with the data. We uploaded several extracts which included Experian’s base data files. Those files contained corporate hierarchies and relevant features such as address, city and website and many others. This added up to millions of rows of data. The team had to perform several cycles of data sampling, understanding, preparation and definition. We did this working very closely with business stakeholders.
In the next sprint, the team performed modeling, which included feature engineering, blocking and evaluation of several machine learning techniques, including binary classification algorithms, logistic regression, neural networks and recurrent neural networks (RNN).
The team determined that RNN in a binary classification achieved the best results with 95 percent accuracy. Matching the hierarchies previously took years of application and manual work. But now with a new RNN model, the model found more matches then the existing process with very good accuracy. In the final sprint, the team deployed, validated and scored additional hierarchies using the IBM Watson Machine Learning deployment service.
In a few months, with the goal of scaling AI to impact all corporate hierarchies in BIS, the team had a validated an approach to a new, innovative AI system for corporate hierarchy matching. An aspect of project was to estimate the computational needs and system design for a full entity matching system. We estimated that to launch a full entity matching system with the current data and a 4-way ensemble of RNNs, Experian would initially have to train hundreds of models. This would require access to a great amount of GPU processing, and we would need to build several components that would have to interact.
We sketched a workflow for the entity matching system that we proposed to be run on IBM Cloud.
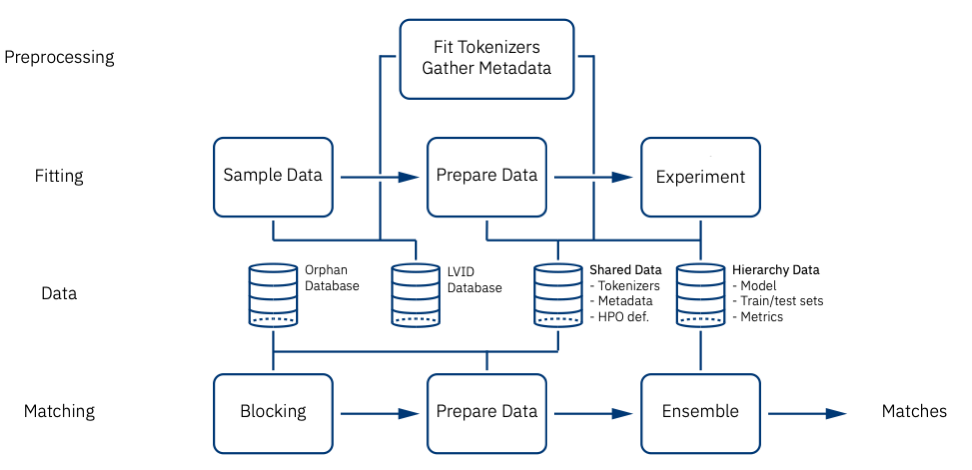
This was just the start. In a short time, the team developed 16 notebooks for data preparation, blocking, modeling and predictions. The language of choice was Python, with a heavy reliance on libraries including Pandas, NumPy and Keras with a Tensorflow backend.
The work set the BIS team on path to free them from a manual process by using AI.
Carlo Appugliese is Machine Learning Program Director IBM Analytics.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht