

For lots of reasons, and some quite appropriate, we tend to think of Deployment as an event. It is more powerful to think of it as a process. The CRoss-Industry Standard Process for Data Mining ("CRISP-DM") has been a powerful influence since its emergence in the 1990s. Its famous six phases terminate with Deployment. So it seems natural that many postpone thinking about it until the end. And when the end is reached, they move on to the next project.
In practice, there is nothing effective nor natural about this behavior. It is also not true to CRISP-DM. Too many organizations pay lip service to CRISP-DM but never scratch the surface. They know the famous circular diagram, but they don’t attend to the 24 tasks within the six phases.
To try to combat this misconception at The Modeling Agency (“TMA”), we introduced The Modeling Practice FrameworkTM (“MPF”). The MPS expands CRISP-DM to Seven Phases and more than 50 tasks. The downside is obvious - it is bit more complicated. But the upside is powerful. It is more project management friendly, and more compatible with the demands of Gantt charts and corporate project management offices.
It has another, even more powerful advantage. If one thinks of the phases as vertical cuts, slicing our labor commitments over time, then you can also think of horizontal slices clarifying WHO is doing the work. We’ve mapped out who does what and when – literally, for every task. We’ve chosen a subway map format to show that, at key points in the process, show how the different roles assemble and then work independently for a time, then assemble again. The key points are like “hubs” in the subway system.
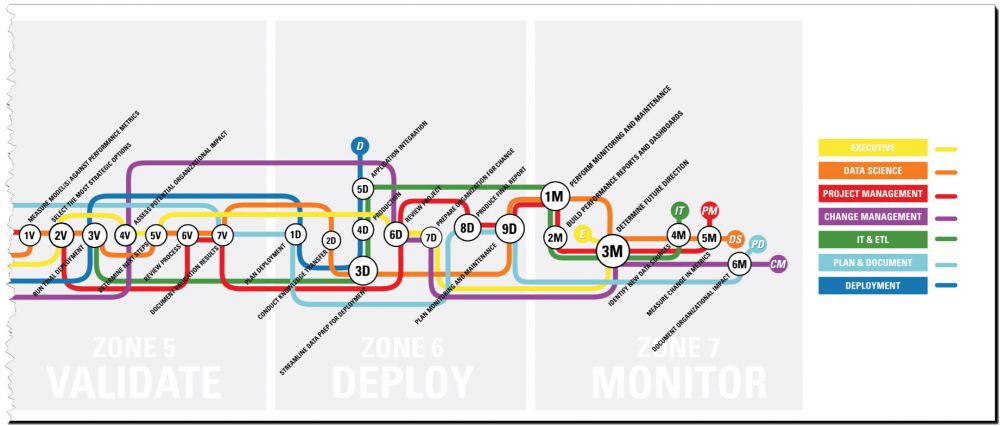
Let’s review a handful of the deployment-related tasks to get a feel for how this works in a project.
Consider Deployment Options
We place this task in the Plan Phase because you must present the project concept to the end users in advance. You don’t need to finalize the deployment in every detail - and wouldn’t want to at this stage. But you do need to confirm that the model has a purpose, fulfills a real need, and will ultimately be productionalized and adopted.
Initiate the Deployment Planning Process
Fairly early in the modeling process you should know what form the model is going to take even though you might be weeks away from have a finished model. For instance, in virtually all supervised learning tasks, a score from zero to one is going to be generated. You almost certainly don’t know which variables will make it into the final model, but you might not know if it is likely to be more or less than 100. You know where you are pulling data from and where you are pushing scores out to. In short, there is a lot that you do know that allows you to build a prototype deployment platform, while concurrently working on the model.
Determine Deployment Readiness
If the premise that you can start on deployment before you finish modeling is correct, then you should circle back and have the two working groups compare notes as you near completion of the model. You can even start to finalize a date when the final model will get shared and then tested. Since the basic structure is known, there is no reason why deployment prototyping cannot begin in earnest. You simply don’t need the final model to do this.
Run a Trial Deployment
The difference between deployment readiness and a trial deployment is who is involved. When it is time for a trial deployment, all of the key players take part - not just the immediate team. End users are involved. Even the C-suite should be updated. A budget needs to be established. This is a true dress rehearsal. In theory, you can run a trial in all departments and all locations, but it is almost always wiser to do a roll out to a fraction of the operation. This is when you will establish your most convincing evidence of the model’s worth.
Distribute a Deployment Plan
CRISP-DM places the writing of a deployment plan in the Deployment Phase, which makes sense within the context of that document. CRISP-DM emphasizes the iterative nature of data mining. So you have to be focused on elements of all the phases at any given time.
However, it is obvious that by the time the deployment phase arrives, you’ve been working off a static deployment plan for weeks or months, though many aspects have likely evolved. At this point, the evolution stops, and you must finalize the plan because you are about to go live. So, at this point, those who have been on periphery of the project will be suddenly involved, debriefed and trained, now that deployment has arrived.
Perform Monitoring and Maintenance
It is a shame that most organizations fully overlook this critical step. The reason is that so many team members break away and move onto new projects after deployment. This is especially true for external resources. Therefore organizations that have utilized an external modeler have to be especially careful to monitor and maintain properly. Frankly, there is no excuse not to do it since monitoring is not a high-bandwidth task. At its most basic, it is simply asking a handful of straightforward questions will suffice:
• Is the Model still fulfilling its intended purpose?
• What was the accuracy of the model during this past cycle?
• Have there been any technical issues during the past cycle?
It is also a shame that organizations fail to implement this simple step because it is an excellent way to mentor a new member of the team. If a simple check list is put into place, many simple calculations can be automated and reduce the time to just a few minutes. Verifying that everything is in place and accuracy has been stable is perfectly appropriate for the newest and most junior member of the team, while providing an excellent learning experience.
Keith McCormick will present two keynotes during the Data Warehousing & Business Intelligence Summit on March 27th and 28th 2019; Model Deployment for Production & Adoption – Why the Last Task Should be the First Discussed; and Addressing Organizational Resistance to Predictive Analytics and Machine Learning. Also afterwards he will present an unique post-conference workshop: Putting Machine Learning to Work.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht