

Het gebruik en de verzameling van data is drastisch aan het veranderen en aan het toenemen. Data wordt nu breder en intensiever gebruikt en steeds meer personen willen er toegang toe hebben. Dit alles zet druk op de architectuur en roept vragen op over hoe lang bestaande constructies overeind zullen blijven.
De toenemende behoefte vanuit de business om met data aan de slag te gaan zorgt ervoor dat afdelingen verschillende ‘data delivery systems’ gaan implementeren. Denk hierbij aan het datawarehouse zoals we het kennen maar ook aan data lakes, data marketplaces, data services en data streaming. Al deze systemen verzamelen en behandelen data uit bronsystemen op een andere manier en dat terwijl zij allemaal te maken krijgen met gedeelde specificaties en vaak ook gedeelde gebruikers. Denk hierbij aan het ETL (Extract, Transform, Load) proces en het vaststellen van definities. Hierdoor ontstaat het risico van data-eilandjes met inconsistente resultaten. Het is ideaal is daarom om een universele architectuur te creëren vanwaar alle wensen voldaan kunnen worden. Op deze manier beschik je over consistente data en voorkom je dat werk dubbel uitgevoerd hoeft te worden. Maar hoe maak je dit ideale beeld een realiteit?
Creëer één centrale Data Hub
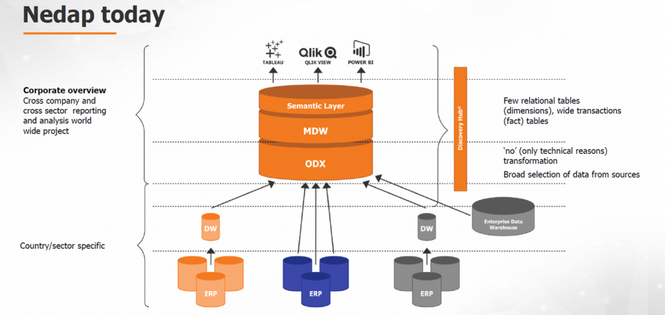
Eén universele architectuur is te zien als een soort hub van waar je business logica kunt beheren om vervolgens de juiste gebruikers op de juiste plek toegang te kunnen geven. Gebruikers hebben namelijk verschillende behoeftes. Een data scientist zou dichter op de bron willen zitten terwijl management toegang wil tot berekende gegevens en key KPI’s. Om deze gebruikers toegang te geven op verschillende niveau’s zonder consistentie te verliezen is een architectuur nodig die mee kan groeien en waarin eenvoudig meerdere bronnen te verbinden zijn. Dit is precies wat de Discovery Hub van TimeXtender doet. Hiermee kun je meerdere datavisualisatie tools eenvoudig laten draaien op dezelfde berekeningen en definities die gemaakt worden in de semantic layer. Zo is zeker dat de hele organisatie met dezelfde gegevens werkt én dat zij toegang krijgt op het benodigde niveau. Data scientists kunnen met de Discovery Hub bijvoorbeeld data halen uit de operational data exchange of hiervanuit bewerken met statische of voorspellende tools zoals R of Python.
Totaaloverzicht
Majken Sander, Solution Architect bij TimeXtender, beschreef de case van Nedap tijdens haar presentatie op de Data Warehousing & Business Intelligence Summit die plaats vond op 20 en 21 maart 2018 in Utrecht. Nedap, een multinationale organisatie gericht op identificatie- en security-oplossingen, beschikte over verschillende bronsystemen en meerdere datavisualisatie-tools (front-ends). Nedap werkte hierdoor met verschillende datatransformaties en berekeningen in de landen waar zij actief zijn en visualiseerde deze data met verschillende analyse tools. Sommige van deze tools waren direct op de databronnen aangesloten terwijl andere werkten met data-extracties.
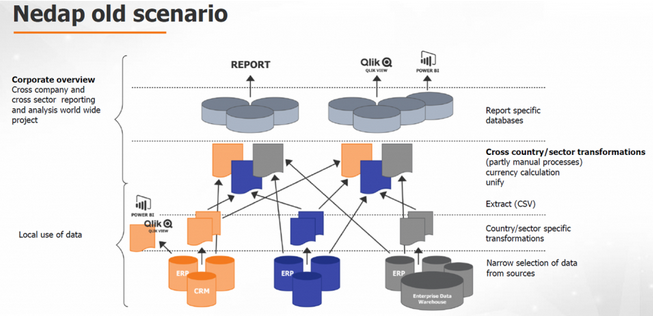
Deze architectuur werkte op zich prima voor specifieke landen, maar maakte het creëren van een totaaloverzicht voor de organisatie heel tijdrovend en moeilijk. Daarnaast bestond de kans dat data verouderd was, doordat data uit het ERP-systeem geëxporteerd moest worden naar een CSV-bestand, voordat het in een datavisualisatietool geladen kon worden. Bovendien was het toevoegen of veranderen van databronnen erg lastig. Door de implementatie van de Discovery Hub beschikt Nedap sneller over accurate data die zij eenvoudig in diverse data-analyse tools kunnen visualiseren en analyseren. Data is in de hub altijd up-to-date en juist en geeft Nedap hierdoor de vrijheid om met verschillende front-end tools te kunnen werken. Veranderingen in bronsystemen worden nu opgevangen in de Hub.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht