

The last Kafka Summit in San Francisco focused on large swaths of discussions around operationally managing Kafka during its upgrade cycle, dealing with large scale Kafka deployments, ensuring recovery and high availability and handling the large data stream ingestion needed by teams who discover Kafka is available in their organizations. Equally important is how to handle the ballooning costs associated with catering to developer teams’ needs for more and better data processing. Companies are struggling with their own successes of deploying and utilizing Kafka in their enterprise.
Kafka Deployments in Containers
Most of the attendees who visited our booth were surprised to find out that running Kafka in containers in production is a reality today. They could not believe the ease of use, performance and most importantly, the manageability they could expect by deploying their Kafka clusters in containers and specifically on the Diamanti Enterprise Kubernetes Platform. The pain points of ballooning costs, scaling, and disaster recovery are all addressed by the technology innovations that Diamanti brings to containers.
By deploying Kafka in Kubernetes, enterprises can expect the following benefits:
• Quick and easy deployment for fastest time to market
• Seamless upgrades with no downtime
• High availability
• With enterprise class container images from vendors like Confluent, it is very easy to achieve elasticity and scale of the Kafka cluster on demand
Additionally, Diamanti Enterprise Kubernetes Platform provides the following benefits:
• Plug-n-play HCI infrastructure
• Superior performance
• Easy disaster recovery with in-cluster or across-the-cluster storage replication
• Guaranteed quality of service (QoS)
Supercharge Apache Kafka with the Diamanti Enterprise Kubernetes Platform
With Kubernetes on a hyperconverged infrastructure like Diamanti, the true potential of Kafka can be unveiled. This is the only way you can really push the limits of Kafka. In order to highlight the level of performance that can be expected from a Kafka cluster running on the Diamanti Enterprise Kubernetes Platform, we demonstrate the most conservative numbers that can be expected with a containerized Kafka cluster.
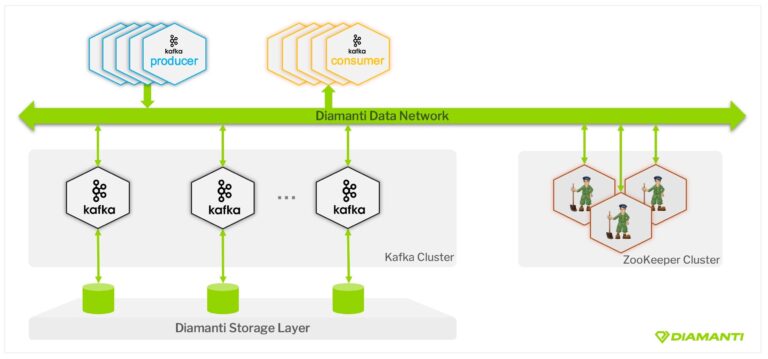
The test used a 3 node Kafka cluster with 6 CPU cores and 32 GB RAM each running a mix of replicated and non-replicated topics. The goal was to show that combining bare-metal and Kubernetes results in a highly performing and easily scalable Kafka deployment which allows business units to consume, process and analyze data, thus enabling quicker decision making.
• Producers can write topics at approximately 3 million writes per second
• Very low and deterministic write latency of 10 milliseconds
• Consumers can read topics at approximately 6 million reads per second

Using Kafka is becoming a defacto necessity in today’s world of fast moving data from multiple sources. It is the driving force behind business intelligence, web applications, IoT and others, as the single point of ingestion and retrieval.
Running Kafka on a Diamanti Enterprise Kubernetes Cluster allows enterprises to rapidly deploy Kafka, while achieving ease of manageability and reduce the total cost of ownership (TCO). Diamanti gives the performance boost with consistency while also providing elasticity and horizontal scaling for Kafka.
Want to learn more? Click here to download the solution brief.
Boris Kurktchiev is Field CTO EMEA at Diamanti.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht