

SQL Server provides custom recommendations by using the Azure SQL Database Advisor, enabling maximal performance. The SQL Database Advisor makes recommendations for creating and dropping indexes, parameterizing queries, and fixing schema issues.
Why is the SQL Database Engine Tuning Advisor (DTA) so different?
The SQL Server Database Engine Tuning Advisor (DTA) has a notoriously bad name in the DBA community for spawning a lot of rubbish indexes, even to the point that it hinders performance more than it helps it forward. Just the sign of _dta_ index on a production server will strike fear in the hearts of seasoned DBAs. As a result, I looked into this Database Advisor with a lot of scepticism and treaded carefully.
One of the mayor differences of the Azure DTA is that it assesses performance by analysing your SQL database usage history. At first, I thought the Azure Advisor used DMVs, but apparently, it works much more intelligently. The Azure DTA generates recommendations that are matched to the database’s workload. We learn that the power of the cloud resides behind this wizard and it actually uses machine learning to decide its actions. Knowing this, it should get better the more people use it. The DTA even provides the option to auto-tune and apply its recommendations automatically. This is an option I can only recommend after carefully testing the results. Once the advisor has gotten to know your database, however, it becomes a very solid option and it came up with some very refreshing solutions.
Pitfall – the clustered index
It is key that the Azure DTA will not reanalyse your clustered indexes. If there is a misaligned clustered index, the Azure DTA will generate a lot of heavy indexes to compensate that misalignment. If you see this behaviour, you should rethink whether you have picked the best possible clustered index. Once you have solved this issue, the advisor’s advice will become to the point and very usable. The impact of a misaligned clustered index in a cloud environment is easily overlooked, but in this case, it will also make this tool less efficient.
Time needed
To generate a valid recommendation, the Azure DTA needs enough of samples for successful machine learning. So, you need data. And the more, the better. If you’re not using your database, the Azure DTA will not produce usable results. This gotcha also makes it rather hard to demo. Why? Well for starters, it requires 18 hours of data just to produce index recommendations, during which you also need enough load to produce adequate results. Besides that, the Azure DTA still needs load to assess if its recommendations were valid and decide to rollback or not. This is more visible when you summarize the auto tuning’s capabilities:
• Time to produce new index recommendations (for a database with daily usage): ± 18 hours
• Delay before T-SQL statement is executed (CREATE INDEX or DROP INDEX): immediately (starts within minutes)
• Time to react to any regressions and revert bad tuning actions: 1 hour
• Delay between implementing consecutive index recommendations: immediately (starts within minutes)
• Time to implement (for a DB with 3 active recommendations): ± 24 hours
Auto evolve with your usage
One of the most frustrating things involved with index maintenance is checking whether it is still adequate and/or, due to query pattern changes, an expensive index has become obsolete. This is where the Azure DTA wizard can really shine. Its recommendations are based on historical database usage, and as the workload evolves over time, the recommendations will automatically adjust to stay relevant. In its current release, it will only drop duplicate indexes to save disk space, so it will not touch so-called unused indexes yet. Once this is completely implemented, it really will provide the database with a possibility to assess expensive indexes in a very straightforward manner. The second great feature is sniffing out parameterization issues. The advisor will propose parameterization fixes when one or more queries that are constantly being recompiled end up with the same query execution plan. This condition opens an opportunity to apply forced parameterization, allowing query plans to be cached and reused in the future improving performance and reducing resource usage.
Fixing schema issues
The fix schema issues recommendations appear when the SQL Database service notices an anomaly in the number of schema-related SQL errors happening on your Azure SQL Database. This typically happens when your database encounters multiple schema-related errors (invalid column name, invalid object name, etc.) within an hour. But what if it made an oopsy? The Azure DTA even has a safety mechanism that automatically reverts the applied recommendation in case a performance regression has been detected.
Even more power?
By combining the Azure DTA with query insight (built on top of the query store), we gain even more insight into the processes of your Azure Database. Similar to the Azure DTA, you do need enough data to work with. If the database has no activity or Query Store was not active during a certain time period, the charts will be empty when displaying that time period. You can enable Query Store at any time if it is not running. Its key features are actually showing the same resource graphs now available in the Query Store, mainly Top Consuming Queries, and the ability to customize these graphs.
The most important one for this blog is the possibility to understand and verify the tuning annotations.
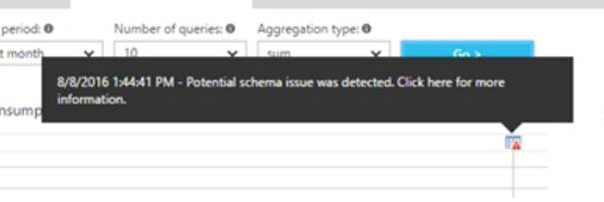
By hovering over one of these annotations, you will see detailed information about this. And if it is an active recommendation, you can even choose to implement it right away, allowing you to assess what kind of impact the applied recommendations have on your database.
So start using them, and you might be pleasantly surprised.
Karel Coenye is senior SQL Server trainer, consultant en Azure Teamlead bij Kohera.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht