

The motto of the Gartner BI Summit Sydney event, in february 2016, was: 'Empowering People with Trusted Data'. What trends are hidden behind these words and what are their consequences for Data Governance?
Does it make sense to use a desktop ETL tool or BI reporting platform? Actually it makes a lot of sense! The current generation of BI and ETL tools are finally approaching a level of usability that a BI analyst can prepare a data set and a sophisticated report on his/her own without any assistance from the IT department. Spreadsheet lovers are reaching the column/row limits of their tools and it is becoming simply too cumbersome to do a very basic data discovery operation with them. I want to skim through these hundreds of columns quickly and blend these two data-sets with simple joins. The new generation of tools are designed with these use cases in mind and do them far more efficiently.
The classical BI platform was deployed centrally, at a huge cost, after considerable delay and with a call for a crusade against spreadsheets. After a heroic struggle the initiative usually failed to outpace the far nimbler sheets of rows and columns.
Today, the roles have reversed. New tools lure their way into business departments with desktop editions. They start small and quickly delivertangible business results and when the house is full of them, then servers and large scale projects take their turn.
Big Data is here to stay - should we trust it?
At the very beginning of the Big Data technologies hype they were a synonym for a container for unstructured content and were expected to sit side by side with a classical data warehouse. Data warehouse professionals quickly realised their other potential. Hey guys, why store core system dumps in these databases where we pay thousands of dollars per CPU? We could store the full history of dumps and it would cost less. Actually why do loads of simple transactions into the core layer of the warehouse by a ETL we pay thousands of dollars per CPU - we can do it far quicker with much cheaper tools …
Big Data is eating the data warehouse technologies from the bottom up. It’s terrific news for BI budget holders - especially when a data warehouse is built on an expensive vendor specific hardware. The savings are can drop of several zeros per year.
On the other hand it may not have to be such great news for end users. The Big Data technologies have two main drawbacks:
So several plus points for technological excellence and economic savings on the one hand but several millions of minus points from business users, because they don’t know what data is available and how to find this out.
What Big Data was expected to be:
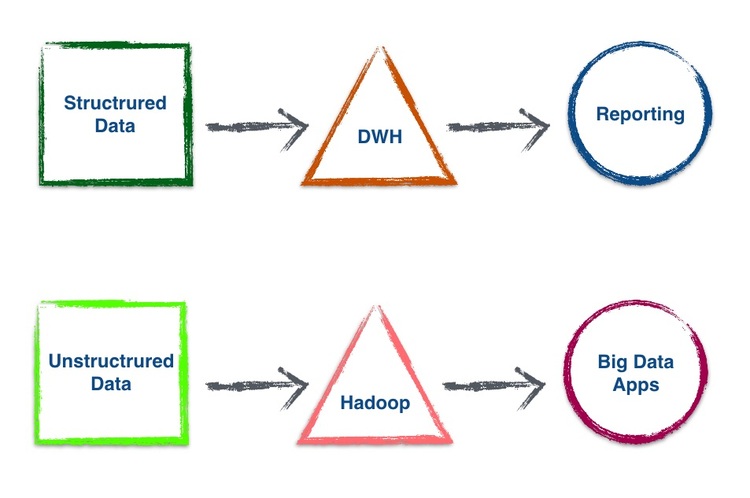
What Big Data is becoming:
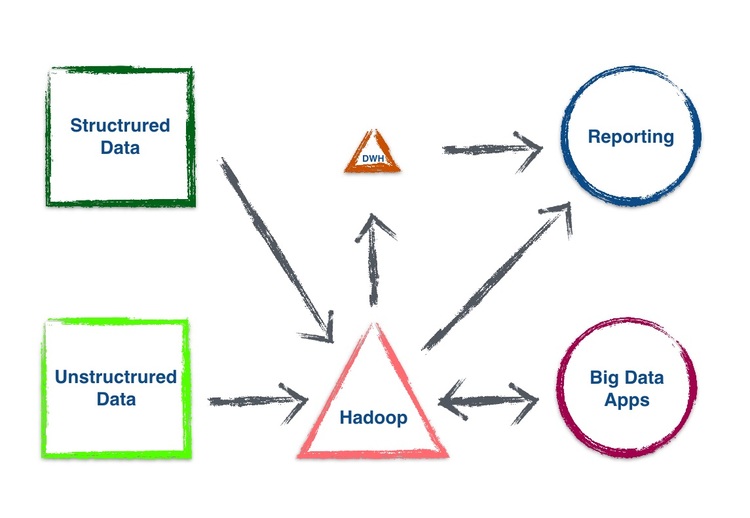
What this means for data governance?
Large bursts of reports, quickly and easily created by users coupled with a huge number of measure stored cheaply means the need for data governance is even more compelling than ever before. The labour cost of producing new information (processing data and interpreting it in a report) is falling significantly.
The cost of finding and making sure that the information can be trusted is surging. This should be a mission for a CDO - make the information more accessible and a bit clearer everyday so the business users are truly “empowered with reliable data”.
Peter Hora is Co-Founder at Semanta.
Note: This blog was posted earlier on the Semanta website with the title ‘Observations from the Gartner BI Summit Sydney event february 2016’, on March 14, 2016.
Semanta wordt in Nederland op de markt gebracht door IntoDQ.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht