

One of the worst things that can happen in mission-critical production environments is loss of data and another is downtime. For a search service that provides end users with easy access to data using natural language, downtime would mean complete halt for those parts of your organization. Even worse if the search service is fueling your online business, it interrupts your customer access and end user experience.
That is why we designed multiple options of backup and disaster recovery for your data served via Cloudera Search, a fully integrated search service fueled by Apache Solr. This blog will highlight these options that come out of the box with our platform.
HDFS to HDFS
If you have the raw data in HDFS (which most do, and which you should!), the most straightforward way to have a hot-warm disaster recovery setup is to use our Backup and Disaster Recovery tool. It allows you to set up regular incremental updates between two clusters. You then have the option of using MapReduce Indexer or Spark Indexer to regularly index the raw data in your recovery cluster and append to a running Solr service in that same recovery cluster. This way you can easily switch over from one Solr service to the backup Solr service if you experience downtime in the original cluster.
The lag would be depending on the network between the clusters and how frequent you transfer data between the clusters. To some extent it would also depend on how long time you need (i.e. how much resources you have available) to complete the MapReduce or Spark indexing workload and append it (using the Cloudera Search GoLive feature) into Solr active indexes on the recovery site.
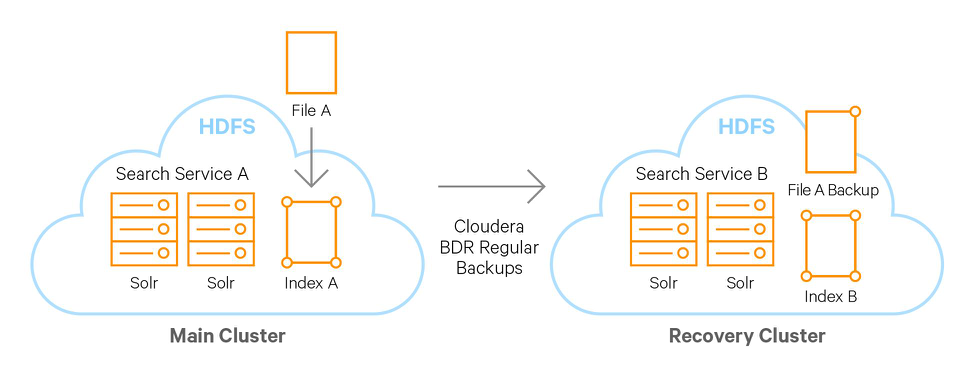
Illustration 1. A File A is stored in HDFS. Regular backups of files can be scheduled through Cloudera BDR to be stored in a recovery cluster. On both clusters Solr, MapReduce or Spark can index new files and append new indexed data to existing actively served indexes in the Solr services of each cluster.
HBase to HBase
If your data is suited to be stored in HBase and you also want that data searchable, our out of the box integration between Solr and HBase makes that possible – both in batch and in real time.
From a DR perspective HBase has excellent capability already to replicate events to a recovery cluster. Nothing prevents you from also having a Cloudera Search service on that cluster as well, consuming the updates and writes to the recovery HBase instance and indexing them in real time on the recovery cluster.
The lag would be depending on the network between the two HBase clusters.
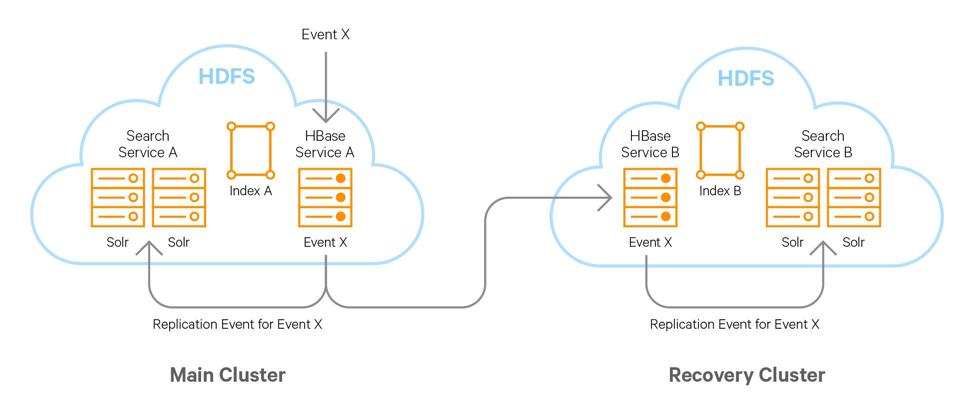
Illustration 2. An event A written to HBase will be replicated to an HBase disaster recovery cluster. This is the same event as the same-cluster Solr service is listening to and indexing in real time, if using the Cloudera Search integration. Similarly a Solr service on the recovery cluster can listen to the HBase disaster recovery cluster and index its replication events.
Index Backup Feature
As described in a previous blog post we have also provided a way to backup index files. Using the index backup tool you can copy your index files in a very efficient and memory-optimized way to a different location. For instance S3 or ADLS, but in the disaster and recovery case perhaps more likely to another HDFS cluster – your recovery cluster. When needed you can then load the indexes back into a Cloudera Search service hosted on your recovery site. Ready to be used by your end-user applications as soon as the index files have finished loading into Solr.
The backup operation is based on Solr’s snapshot capability. It allows to capture a snapshot of a consistent state of index data for an index in Solr. Using Hadoop DistCp to copy the index and associated metadata to elsewhere. Where elsewhere could be a different location in HDFS, same or different cluster, or a cloud object store (e.g. S3).
As the snapshot creation is a reservation of data and metadata, not even a full copy, the lag in this case more depends on if you have a ready-to-go Solr service on your recovery cluster and how long time it takes for that size of index to be loaded into that service.
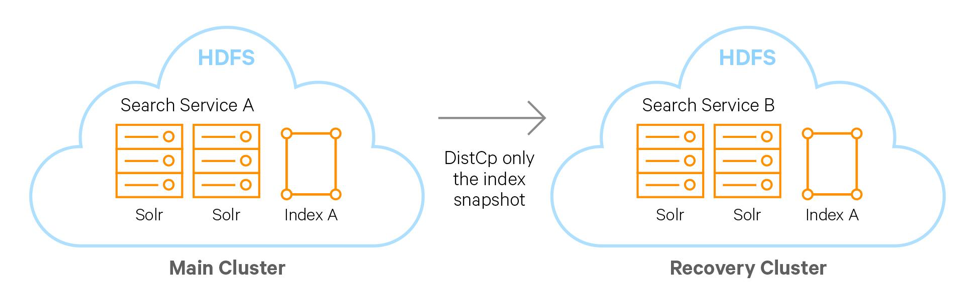
Illustration 3. At a high level, the steps to back-up a Solr collection are as follows:: a) Create a snapshot.; b) If you are exporting the snapshot to a remote cluster, prepare the snapshot for export; c) Export the snapshot to either the local cluster or a remote one. This step uses the Hadoop DistCP utility.
As a side note, this feature is also very useful for backing up your indexes before you make a huge change in your environment, e.g. a major upgrade for instance. It is always wise to backup your data including indexes, to lower risk of data loss. You can read more about how to setup and utilize the Cloudera Search backup utility in the product documentation.
Solr CDCR
The future holds the promise of a Solr to Solr replication feature as well, a.k.a. CDCR. This is still maturing upstream and will need some time to further progress before it can be considered for mission critical production environments. Once it matures we will evaluate its value in addition to all our existing options of recovery for Search. The above solutions, presented in this blog, are production proven and provides a very good coverage along with flexibility for today’s workloads.
Our Recommendations
It is always wise to backup your data (including indexes) on a regular basis. It is also wise to keep your raw data around, in case you want to change your mind later on how you process it (or how you index it). There is cost-effective technology to provide for the option of storing all your data, so why not take advantage of it?
We hope you learned something new with this blog post on disaster recovery and backup options for Cloudera Search. We encourage you to take advantage of these out-of-the-box valuable features that our integrated search provides you. Only Cloudera Search is able to provide you this variety and flexibility of backup and recovery options, to suit your different recovery needs.
Eva Nahari is Director of Product Management at Cloudera.


27 t/m 29 oktober 2025Praktische driedaagse workshop met internationaal gerenommeerde trainer Lawrence Corr over het modelleren Datawarehouse / BI systemen op basis van dimensioneel modelleren. De workshop wordt ondersteund met vele oefeningen en pra...
29 en 30 oktober 2025 Deze 2-daagse cursus is ontworpen om dataprofessionals te voorzien van de kennis en praktische vaardigheden die nodig zijn om Knowledge Graphs en Large Language Models (LLM's) te integreren in hun workflows voor datamodel...
3 t/m 5 november 2025Praktische workshop met internationaal gerenommeerde spreker Alec Sharp over het modelleren met Entity-Relationship vanuit business perspectief. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...
11 en 12 november 2025 Organisaties hebben behoefte aan data science, selfservice BI, embedded BI, edge analytics en klantgedreven BI. Vaak is het dan ook tijd voor een nieuwe, toekomstbestendige data-architectuur. Dit tweedaagse seminar geeft antwoo...
17 t/m 19 november 2025 De DAMA DMBoK2 beschrijft 11 disciplines van Data Management, waarbij Data Governance centraal staat. De Certified Data Management Professional (CDMP) certificatie biedt een traject voor het inleidende niveau (Associate) tot...
25 en 26 november 2025 Worstelt u met de implementatie van data governance of de afstemming tussen teams? Deze baanbrekende workshop introduceert de Data Governance Sprint - een efficiënte, gestructureerde aanpak om uw initiatieven op het...
26 november 2025 Workshop met BPM-specialist Christian Gijsels over AI-Gedreven Business Analyse met ChatGPT. Kunstmatige Intelligentie, ongetwijfeld een van de meest baanbrekende technologieën tot nu toe, opent nieuwe deuren voor analisten met ...
8 t/m 10 juni 2026Praktische driedaagse workshop met internationaal gerenommeerde spreker Alec Sharp over herkennen, beschrijven en ontwerpen van business processen. De workshop wordt ondersteund met praktijkvoorbeelden en duidelijke, herbruikbare ri...

Deel dit bericht